Optimization Techniques and Design Fundamentals
This chapter describes how the SteelHead optimizes data, the factors you need to consider when designing your SteelHead deployment, and how and when to implement the most commonly used SteelHead features.
This chapter includes the following sections:
How SteelHeads Optimize Data
The SteelHead optimizes data in the following ways:
The causes for slow throughput in WANs are well known: high delay (round-trip time or latency), limited bandwidth, and chatty application protocols. Large enterprises spend a significant portion of their information technology budgets on storage and networks. Much of the budgets are spent to compensate for slow throughput by deploying redundant servers and storage and the required backup equipment. SteelHeads enable you to consolidate and centralize key IT resources to save money, simplify key business processes, and improve productivity.
RiOS is the software that powers the SteelHead and SteelCentral Controller for SteelHead Mobile. With RiOS, you can solve a range of problems affecting WANs and application performance, including:
• insufficient WAN bandwidth.
• inefficient transport protocols in high-latency environments.
• inefficient application protocols in high-latency environments.
RiOS intercepts client-server connections without interfering with normal client-server interactions, file semantics, or protocols. All client requests are passed through to the server normally, although relevant traffic is optimized to improve performance.
Data Streamlining
With data streamlining, SteelHeads and SteelCentral Controller for SteelHead Mobile can reduce WAN bandwidth utilization by 65 to 98% for TCP-based applications. This section includes the following topics:
Scalable Data Referencing
In addition to traditional techniques like data compression, RiOS also uses a Riverbed proprietary algorithm called Scalable Data Referencing (SDR). RiOS SDR breaks up TCP data streams into unique data chunks that are stored on the hard disks (RiOS data store) of the device running RiOS (a SteelHead or SteelCentral Controller for SteelHead Mobile host system). Each data chunk is assigned a unique integer label (reference) before it is sent to a peer RiOS device across the WAN. When the same byte sequence occurs in future transmissions from clients or servers, the reference is sent across the WAN instead of the raw data chunk. The peer RiOS device (a SteelHead or SteelCentral Controller for SteelHead Mobile host system) uses this reference to find the original data chunk on its RiOS data store and reconstruct the original TCP data stream.
Files and other data structures can be accelerated by data streamlining even when they are transferred using different applications. For example, a file that is initially transferred through CIFS is accelerated when it is transferred again through FTP.
Applications that encode data in a different format when they transmit over the WAN can also be accelerated by data streamlining. For example, Microsoft Exchange uses the MAPI protocol to encode file attachments prior to sending them to Microsoft Outlook clients. As a part of its MAPI-specific optimized connections, the RiOS decodes the data before applying SDR. This decoding enables the SteelHead to recognize byte sequences in file attachments in their native form when the file is subsequently transferred through FTP or copied to a CIFS file share.
Bidirectional Synchronized RiOS Data Store
Data and references are maintained in persistent storage in the data store within each RiOS device and are stable across reboots and upgrades. To provide further longevity and safety, local SteelHead pairs optionally keep their data stores fully synchronized bidirectionally at all times. Bidirectional synchronization ensures that the failure of a single SteelHead does not force remote SteelHeads to send previously transmitted data chunks. This feature is especially useful when the local SteelHeads are deployed in a network cluster, such as a primary and backup deployment, a serial cluster, or a WCCP cluster.
For information about primary and backup deployments, see
Redundancy and Clustering. For information about serial cluster deployments, see
Serial Cluster Deployments. For information about WCCP deployments, see
WCCP Virtual In-Path Deployments.
Unified RiOS Data Store
A key Riverbed innovation is the unified data store that data streamlining uses to reduce bandwidth usage. After a data pattern is stored on the disk of a SteelHead or Mobile Controller peer, it can be leveraged for transfers to any other SteelHead or Mobile Controller peer, across all accelerated applications. Data is not duplicated within the RiOS data store, even if it is used in different applications, in different data transfer directions, or with new peers. The unified data store ensures that RiOS uses its disk space as efficiently as possible, even with thousands of remote SteelHeads or Mobile Controller peers.
Transport Streamlining
SteelHeads use a generic latency optimization technique called transport streamlining. This section includes the following topics:
You can find additional information about the transport streaming modes in
QoS Configuration and Integration and
Satellite Optimization.
Overview of Transport Streamlining
TCP connections suffer a lack of performance due to delay, loss, and other factors. There are many articles written about and other information available regarding how to choose the client and server TCP settings and TCP algorithms most appropriate for various environments. For example, without proper tuning, a TCP connection might never be able to fill the available bandwidth between two locations. You must consider the TCP window sizes used during the lifespan of a connection. If the TCP window size is not large enough, then the sender cannot consume the available bandwidth. You must also consider packet loss due to congestion or link quality.
In many cases, packet loss is an indication to a TCP congestion avoidance algorithm that there is congestion, and congestion is a signal to the sender to slow down. The sender then can choose at which rate to slow down. The sender can:
• undergo a multiplicative decrease: for example, send at one half the previous rate.
• use other calculations to determine a slightly lower rate, just before the point at which congestion occurred.
A SteelHead deployed on the network can automate much of the manual analysis, research, and tuning necessary to achieve optimal performance, while providing you with options to fine tune. Collectively, these settings in the SteelHead are referred to as transport streamlining. The objective of transport streamlining is to mitigate the effects of WANs between client and server. Transport streamlining uses a set of standards-based and proprietary techniques to optimize TCP traffic between SteelHeads. These techniques:
• ensure that efficient retransmission methods are used (such as TCP selective acknowledgments).
• negotiate optimal TCP window sizes to minimize the impact of latency on throughput.
• maximize throughput across a wide range of WAN links.
Additionally, a goal for selecting any TCP setting and congestion avoidance algorithm and using WAN optimization appliances is to find a balance between two extremes: acting fair and being cooperative by sharing available bandwidth with coexisting flows on one end of the spectrum, or acting aggressive by trying to achieve maximum throughput at the expense of other flows on the opposite end of the spectrum. Being on the former end indicates that throughput suffers, and being on the latter end indicates that your network is susceptible to congestion collapse.
By default, the SteelHeads use standard TCP (as defined in RFC 793) to communicate between peers. This type of TCP algorithm is a loss-based algorithm that relies on the TCP algorithm to calculate the effective throughput for any given connection based on packet loss. Additionally, SteelHead peers automatically implement extensions to RFC 793 to provide further enhancements for congestion control beyond that of a standard TCP connection.
Alternatively, you can configure SteelHeads to use a delay-based algorithm called bandwidth estimation. The purpose of bandwidth estimation is to calculate the rate, based on the delay of the link, to recover more gracefully in the presence of packet loss.
In higher-throughput environments you can enable high-speed TCP (HS-TCP), which is a high-speed loss-based algorithm (as defined in RFC 3649) on the SteelHeads to achieve high throughput for links with high bandwidth and high latency. This TCP algorithm shifts toward the more aggressive side of the spectrum. Furthermore, you can shift even further toward the aggressive side of the spectrum, sacrificing fairness, by selecting the maximum TCP (MX-TCP) feature for traffic that you want to transmit over the WAN at a rate defined by the QoS class.
Configuring MX-TCP through the QoS settings leverages QoS features to help protect other traffic and gives you the parameters, such as minimum and maximum percentages of the available bandwidth that TCP connections matching the class can consume. Although not appropriate for all environments, MX-TCP can maintain data transfer throughput in which adverse network conditions, such as abnormally high packet loss, impair performance. Data transfer is maintained without inserting error correction packets over the WAN through forward error correction (FEC). MX-TCP effectively handles packet loss without a decrease in throughput typically experienced with TCP.
The TCP algorithms that rely on loss or delay calculations to determine the throughput should have an appropriate-sized buffer. You can configure the buffer size and choose the TCP algorithm in the Transport Settings page. The default buffer is 262,140 bytes, which should cover any connection of 20 Mbps or less with a round-trip delay up to 100 ms. This connection speed and round-trip delay composes most branch office environments connecting to a data center or hub site.
The following list is a high-level summary of each SteelHead TCP congestion avoidance algorithm:
• Standard TCP - Standard TCP is a standards-based implementation of TCP and is the default setting in the SteelHead. Standard TCP is a WAN-friendly TCP stack and is not aggressive towards other traffic. Additionally, standard TCP benefits from the higher TCP WAN buffers, which are used by default for each connection between SteelHeads.
• Bandwidth estimation - Bandwidth estimation is the delay-based algorithm that incorporates many of the features of standard TCP and includes calculation of RTT and bytes acknowledged. This additional calculation avoids the multiplicative decrease in rate detected in other TCP algorithms in the presence of packet loss. Bandwidth estimation is also appropriate for environments in which there is variable bandwidth and delay.
• HighSpeed TCP (HS-TCP) - HS-TCP is efficient in long fat networks (LFNs) in which you have large WAN circuits (50 Mbps and above) over long distances. Typically, you use HS-TCP when you have a few long-lived replicated or backup flows. HS-TCP is designed for high-bandwidth and high-delay networks that have a low rate of packet loss due to corruption (bit errors). HS-TCP has a few advantages over standard TCP for LFNs. Standard TCP will backoff (slow down the transmission rate) in the presence of packet loss, causing connections to under use the bandwidth.
Also, standard TCP is not as aggressive during the TCP slow-start period to rapidly grow to the available bandwidth. HS-TCP uses a combination of calculations to rapidly fill the link and minimize backoff in the presence of loss. These techniques are documented in RFC 3649. HS-TCP is not beneficial for satellite links because the TCP congestion window recovery requires too many round trips or is too slow. HS-TCP requires that you adjust WAN buffers on the SteelHeads to be equal to 2 x BDP, where bandwidth-delay product (BDP) is the product of the WAN bandwidth and round-trip latency between locations. For more specific settings, see
Storage Area Network Replication.
• SkipWare Space Communications Protocol Standards (SCPS) per connection - SCPS per connection is for satellite links with few or no packet drops due to corruption. SCPS per connection requires a separate license.
• SCPS error tolerance - SCPS error tolerance is for satellite links that have packet drops due to corruption. You must have a separate license to activate SCPS error tolerance.
The following list is a high-level summary of additional modes that alter the SteelHead TCP congestion avoidance algorithm:
• MX-TCP - MX-TCP is ideal for dedicated links, or to compensate for poor link quality (propagation issues, noise, and so on) or packet drops due to network congestion. The objective of MX-TCP is to achieve maximum TCP throughput. MX-TCP alters TCP by disabling the congestion control algorithm and sending traffic up to a rate you configure, regardless of link conditions. Additionally, MX-TCP can share any excess bandwidth with other QoS classes through adaptive MX-TCP. MX-TCP requires knowledge of the amount of bandwidth available for a given QoS class because, provided that enough traffic matches the QoS class, connections using MX-TCP attempt to consume the bandwidth allotted without regard to any other traffic.
• Rate pacing - Rate pacing is a combination of MX-TCP and a TCP congestion avoidance algorithm. You use rate pacing commonly in satellite environments, but you can use it in terrestrial connections as well. The combination of MX-TCP and a TCP congestion avoidance algorithm allows rate pacing to take the best from both features. Rate pacing leverages the rate configured for an MX-TCP QoS class to minimize buffer delays, but can adjust to the presence of loss due to network congestion.
For additional information about transport streamlining mode options, see the following topics:
Connection Pooling
Connection pooling adds a benefit to transport streamlining by minimizing the time for an optimized connection to set up.
Some application protocols, such as HTTP, use many rapidly created, short-lived TCP connections. To optimize these protocols, SteelHeads create pools of idle TCP connections. When a client tries to create a new connection to a previously visited server, the SteelHead uses a TCP connection from its pool of connections. Thus the client and the SteelHead do not have to wait for a three-way TCP handshake to finish across the WAN. This feature is called connection pooling. Connection pooling is available only for connections using the correct addressing WAN visibility mode.
Transport streamlining ensures that there is always a one-to-one ratio for active TCP connections between SteelHeads and the TCP connections to clients and servers. Regardless of the WAN visibility mode in use, SteelHeads do not tunnel or perform multiplexing and demultiplexing of data across connections.
For information about correct addressing modes, see
WAN Visibility Modes. For information about HTTP optimization, see the
SteelHead Deployment Guide - Protocols.
TCP Automatic Detection
One best practice you can consider for nearly every deployment is the TCP automatic detection feature on the data center SteelHeads. This feature allows the data center SteelHead to reflect the TCP algorithm in use by the peer. The benefit is that you can select the appropriate TCP algorithm for the remote branch office, and the data center SteelHead uses that TCP algorithm for connections. If SteelHeads on both sides of an optimized connection use the automatic detection feature, then standard TCP is used.
SteelCentral Controller for SteelHead Mobile TCP Transport Modes
This section briefly describes specific transport streamlining modes that operate with SteelCentral Controller for SteelHead Mobile.
HS-TCP is not the best choice for interoperating in a SteelCentral Controller for SteelHead Mobile environment because it is designed for LFNs (high bandwidth and high delay). Essentially, the throughput is about equal to standard TCP.
MX-TCP is a sender-side modification (configured on the server side) and is used to send data at a specified rate. When SteelCentral Controller for SteelHead Mobile is functioning on the receiving side, it can be difficult to deploy MX-TCP on the server side. The issue is defining a sending rate in which it might not be practical to determine the bandwidth that a client can receive on their mobile device because it is unknown and variable.
Tuning SteelHeads for High-Latency Links
Riverbed recommends that you gather WAN delay (commonly expressed as RTT), packet-loss rates, and link bandwidth to better understand the WAN characteristics so that you can make adjustments to the default transport streamlining settings. Also, understanding the types of workloads (long-lived, high-throughput, client-to-server traffic, mobile, and so on) is valuable information for you to appropriately select the best transport streamlining settings.
Specific settings for high-speed data replication are covered in
Storage Area Network Replication. The settings described in this chapter approximate when you can adjust the transport streamlining settings to improve throughput.
TCP Algorithm Selection
The default SteelHead settings are appropriate in most deployment environments. Based on RTT, bandwidth, and loss, you can optionally choose different transport streamlining settings. A solid approach to selecting the TCP algorithm found on the Transport Settings page is to use the automatic detection feature (auto-detect) on the data center SteelHead. The benefit to automatic detection is that the data center SteelHead reflects the choice of TCP algorithm in use at the remote site. You select the TCP algorithm at the remote site based on WAN bandwidth, RTT, and loss.
A general guideline is that any connection more than 50 Mbps can benefit from using HS-TCP, unless the connection is over satellite (delay greater than 500 ms). You can use MX-TCP for high data rates if the end-to-end bandwidth is known and dedicated.
When you are factoring in loss at lower-speed circuits, consider using bandwidth estimation. When planning, consider when packet loss is greater than 0.1%. Typically, MPLS networks are below 0.1% packet loss, while other communication networks can be higher. For any satellite connection, the appropriate choices are SCPS (if licensed) or bandwidth estimation.
For specific implementation details, see
Satellite Optimization.
WAN Buffers
After you select the TCP algorithm, another setting to consider is the WAN-send and WAN-receive buffers. You can use bandwidth and RTT to determine the BDP. BDP is a multiplication of bandwidth and RTT, and it is commonly divided by 8 and expressed in bytes. To get better performance, the SteelHead as a TCP proxy typically uses two times BDP as its WAN-send and WAN-receive buffer. For asymmetry, you can have the WAN-send buffer reflect the bandwidth and delay in the transmit direction, while the WAN-receive buffer reflects the bandwidth and delay in the receive direction. You do not have to adjust the buffer settings unless there is a are only a few connections and you want to consume most or all of the available WAN bandwidth.
Application Streamlining
You can apply application-specific optimization for specific application protocols. For SteelHeads using RiOS 6.0 or later, application streamlining includes the following protocols:
• CIFS for Windows and Mac clients (Windows file sharing, backup and replication, and other Windows-based applications)
• MAPI, Outlook Anywhere (RPC over HTTP) and MAPI over HTTP, Microsoft Exchange 5.5, 2000, 2003, 2007, 2010, 2013, and 2016)
• NFSv3 for UNIX file sharing
• TDS for Microsoft SQL Server
• HTTP
• HTTPS and SSL
• IMAP-over-SSL
• Oracle 9i, which comes with Oracle Applications 11i
• Oracle10gR2, which comes with Oracle E-Business Suite R12
• Lotus Notes 6.0 or later
• Encrypted Lotus Notes
• ICA Client Drive Mapping
• support for multi-stream ICA and multi-port ICA
Protocol-specific optimization reduces the number of round trips over the WAN for common actions and help move through data obfuscation and encryption by:
• opening and editing documents on remote file servers (CIFS).
• sending and receiving attachments (MAPI and Lotus Notes).
• viewing remote intranet sites (HTTP).
• securely performing RiOS SDR for SSL-encrypted transmissions (HTTPS).
For more information about application streamlining, see the SteelHead Deployment Guide - Protocols.
Management Streamlining
Developed by Riverbed, management streamlining simplifies the deployment and management of RiOS devices, including both hardware and software:
• Autodiscovery Protocol - Autodiscovery enables SteelHeads and SteelCentral Controller for SteelHead Mobile to automatically find remote SteelHeads and begin to optimize traffic. Autodiscovery avoids the requirement of having to define lengthy and complex network configurations on SteelHeads. The autodiscovery process enables administrators to:
– control and secure connections.
– specify which traffic is to be optimized.
– specify peers for optimization.
• SCC - The SCC enables new, remote SteelHeads to be automatically configured and monitored. It also provides a single view of the overall optimization benefit and health of the SteelHead network.
• Mobile Controller - The Mobile Controller is the management appliance that you use to track the individual health and performance of each deployed software client and to manage enterprise client licensing. The Mobile Controller enables you to see who is connected, view their data reduction statistics, and perform support operations such as resetting connections, pulling logs, and automatically generating traces for troubleshooting. You can perform all of these management tasks without end-user input.
RiOS Data Store Synchronization
RiOS data store synchronization enables pairs of local SteelHeads to synchronize their data stores with each other, even while they are optimizing connections. RiOS data store synchronization is typically used to ensure that if a SteelHead fails, no loss of potential bandwidth savings occurs, because the data segments and references are on the other SteelHead. This section includes the following topics:
You can use RiOS data store synchronization for physical in-path, virtual in-path, or out-of-path deployments. You enable synchronization on two SteelHeads: one as the synchronization primary, and the other as the synchronization backup.
The traffic for RiOS data store synchronization is transferred through either the SteelHead primary or auxiliary network interfaces, not the in-path interfaces.
RiOS data store synchronization is a bidirectional operation between two SteelHeads, regardless of which deployment model you use. The SteelHead primary and backup designations are relevant only in the initial configuration, when the primary SteelHead RiOS data store essentially overwrites the backup SteelHead RiOS data store.
RiOS Data Store Synchronization Requirements
The synchronization primary and its backup:
• must have the same hardware model.
• must be running the same version of RiOS.
• do not have to be in the same physical location. If they are in different physical locations, they must be connected through a fast, reliable LAN connection with minimal latency.
Note: Before you replace a synchronization primary for any reason, Riverbed recommends that you make the synchronization backup the new synchronization primary. Therefore, the new primary (the former backup) can warm the new (replacement) SteelHead, ensuring that the most data is optimized and none is lost.
RiOS Data Store Error Alarms
You receive an email notification if an error occurs in the RiOS data store. The RiOS data store alarms are enabled by default.
If the alarm was caused by an unintended change to the configuration, you can change the configuration to match the old RiOS data store settings again and then restart the optimization service (without clearing the data store) to reset the alarm. In certain situations you might need to clear the RiOS data store. Typical configuration changes that require a clear data store are changes to the data store encryption type or enabling the extended peer table.
To clear the data store of data, restart the optimization service and click Clear the Data Store.
For more information about the RiOS data store error alarm, see the SteelHead Management Console User’s Guide.
Choosing the Right SteelHead Model
Generally, you select a SteelHead model based on the number of users, the bandwidth requirements, and the applications used at the deployment site. However:
• If you do not want to optimize applications that transfer large amounts of data (for example, WAN-based backup or restore operations, system image, or update distribution), choose your SteelHead model based on the amount of bandwidth and number of concurrent connections at your site.
• If you want to optimize applications that transfer large amounts of data, choose your SteelHead model based on the amount of bandwidth, the number of concurrent connections at your site, and the size of the RiOS data store.
• If you want to use SteelHead to enforce network Quality of Service (QoS), consider the SteelHead model QoS bandwidth in addition to the optimization criteria you need.
You can also consider high availability, redundancy, data protection, or other design-related requirements when you select a SteelHead. SteelHead models vary according to the following attributes:
• Optimized WAN bandwidth license limit
• Maximum number of concurrent TCP connections that can be optimized
• Maximum number of possible in-path interfaces
• Availability of RAID and solid-state drives (SSD) for the RiOS data store
• Availability of fiber interfaces
• Availability of redundant power supplies
• Availability of hardware-based compression card
• Availability of VSP
• Upgrade options through software licenses
All SteelHead models have the following specifications that are used to determine the amount of traffic that a single SteelHead can optimize:
• Number of concurrent TCP connections - Each SteelHead model can optimize a certain number of concurrent TCP connections.
The number of TCP concurrent connections that you need for optimization depends on the number of users at your site, the applications that you use, and whether you want to optimize all applications or just a few of them. When planning corporate enterprise deployments, Riverbed recommends that you use ratios of 5 to 15 concurrent connections per user if full optimization is desired, depending on the applications being used.
If the number of connections that you want to optimize exceed the limit of the SteelHead model, the excess connections are passed through unoptimized by the SteelHead.
The TCP protocol only supports approximately 64,000 ports per IP address for outbound or inbound connections to or from a unique IP-Port pair. If your design or environment requires you to support more than 64,000 concurrent connections to a single IP address for optimization, Riverbed recommends that you use multiple in-path interfaces or service port mapping.
• Number of encrypted TCP connections - The SteelHead transparently optimizes encrypted connections by first decrypting it to optimize the payload, and then reencrypting it for secure transport over the WAN. Examples of encrypted applications and protocols that a SteelHead can optimize include HTTP Secure (or HTTPS/SSL) and Microsoft Outlook/Outlook Anywhere traffic (or encrypted-MAPI, RPC-over-HTTPS).
If you have predominately encrypted connections, contact your Riverbed account team for assistance with determining the appropriate model.
• WAN bandwidth limit - Each SteelHead model has a limit on the rate at which it sends optimized traffic toward the WAN. You might not need a SteelHead model that is rated for the same bandwidth available at the deployment site; however, Riverbed recommends that you make sure that the selected appliance is not a bottleneck for the outbound optimized traffic. The optimized WAN bandwidth limit applies only to optimized traffic.
When a SteelHead reaches its optimized WAN bandwidth limit, it begins shaping optimized traffic along this limit. New connections continue to be optimized as long as the concurrent TCP connection count is not exceeded. The optimized WAN bandwidth limit is not to be confused with the QoS WAN bandwidth limit that applies to both optimized and pass-through traffic.
• RiOS data store size - Each SteelHead model has a fixed amount of disk space available for RiOS SDR. Because SDR stores unique patterns of data, the amount of data store space needed by a deployed SteelHead differs from the amount needed by applications or file servers. For the best optimization possible, the RiOS data store must be large enough to hold all of the commonly accessed data at a site. Old data that is recorded in the RiOS data store might eventually be overwritten by new data, depending on traffic patterns.
At sites where applications transfer large amounts of data (for example, WAN-based backup or restore operations, system image, or update distribution), you must not select the SteelHead model based only on the amount of bandwidth and number of concurrent connections at the site, but also on the size of RiOS data store. Sites without these applications are typically sized by considering the bandwidth and number of concurrent connections.
If your requirements exceed the capacity of a single SteelHead, consider a SteelHead cluster. There are many ways to cluster SteelHeads and scale up the total optimized capacity and provide redundancy.
For more information about clustering, see
In-Path Redundancy and Clustering Examples.
You need to determine the SteelHead platform best suited for your deployment. SteelHeads are available in the following platforms:
• Physical - the SteelHead CX and SteelHead EX appliances
• Virtual - the SteelHead-v for VMware vSphere and Microsoft Hyper-V hypervisors
• Cloud/SaaS - the SteelHead-c for Amazon Web Services and Microsoft Azure
• Mobile - the Mobile Controller and the SteelHead Mobile client for Windows and Mac-based laptops
Note: The Hyper-V hypervisor platform does not support the Riverbed bypass NIC card.
The SteelHead CX model is a dedicated WAN optimization solution that supports a rich set of application protocols that includes but is not limited to Microsoft Exchange, CIFS, SMB, SharePoint, HTTP/HTTPS, Lotus Notes, FCIP, SRDF, and SnapMirror.
The SteelHead EX model combines WAN optimization, virtualization, and storage consolidation into a single appliance for the branch office. Virtualization is provided by VSP. VSP is a VMware-based hypervisor built into RiOS. VSP enables you to virtualize and localize multiple branch services such as print, DNS, and DHCP, into a single appliance for the branch office. Storage consolidation is provided by the SteelFusion Edge, a virtual edge service that enables end users in a branch office to access and write to centralized storage in the data center over the WAN at local speeds. SteelFusion Edge is available on the SteelHead EX as a license upgrade option.
A complete enterprise WAN optimization solution can require the deployment of multiple SteelHead platforms. For example, you have hosted some of your applications in the cloud and you do want to optimize the traffic for these applications. In this deployment you need a physical SteelHead in the data center (client side) and a SteelHead-c in the SaaS vendor cloud (server side).
You might also like to optimize traffic for your internally hosted business applications between their mobile users and data center. Your mobile users access their data center over the internet using a VPN. In this deployment you need a SteelHead Mobile client in the mobile user laptop (client-side) and a nonmobile SteelHead on the server-side. In addition, you need to deploy a Mobile Controller in your data center to manage and license your SteelHead Mobile clients.
If you need help planning, designing, deploying, or operating your SteelHeads, Riverbed offers consulting services directly and through Riverbed authorized partners. For details, contact Riverbed Professional Services by email at
proserve@riverbed.com or go to
http://www.riverbed.com/services-training/Services-Training.html.
Deployment Modes for the SteelHead
You can deploy SteelHeads into the network in many different ways. Deployment modes available for the SteelHeads include:
• Physical In-Path - In a physical in-path deployment, the SteelHead is physically in the direct path between clients and servers. In-path designs are the simplest to configure and manage, and they are the most common type of SteelHead deployment, even for large sites. Many variations of physical in-path deployments are possible to account for redundancy, clustering, and asymmetric traffic flows.
• Virtual In-Path - In a virtual in-path deployment, you can use a redirection mechanism (like WCCP, PBR, or Layer-4 switching) to place the SteelHead virtually in the path between clients and servers.
• Out-of-Path - In an out-of-path deployment, the SteelHead is not in the direct path between the client and the server. In an out‑of‑path deployment, the SteelHead acts as a proxy. This type of deployment might be suitable for locations where physical in-path or virtual in-path configurations are not possible. However, out-of-path deployments have several drawbacks that you must be aware of.
Autodiscovery Protocol
This section describes the SteelHead autodiscovery protocol. This section includes the following topics:
Autodiscovery enables SteelHeads to automatically find remote SteelHeads and to optimize traffic with them. Autodiscovery relieves you of having to manually configure the SteelHeads with large amounts of network information.
The autodiscovery process enables you to:
• control and secure connections.
• specify which traffic is optimized.
• specify how remote peers are selected for optimization.
The types of autodiscovery are as follows:
• Original Autodiscovery - Automatically finds the first remote SteelHead along the connection path.
• Enhanced Autodiscovery (available in RiOS 4.0.x or later) - Automatically finds the last SteelHead along the connection path.
Most SteelHead deployments use autodiscovery. You can also manually configure SteelHead pairing using fixed-target in-path rules, but this approach requires ongoing configuration. Fixed-target rules also require tracking new subnets that are present in the network and for which SteelHeads are responsible for optimizing the traffic.
You can use autodiscovery if the SteelHeads are deployed physically in-path or virtually in-path (such as WCCP or PBR). The following section describes physically in-path SteelHeads, but the packet flow is identical to a virtual in-path deployment.
For information about fixed-target in-path rules, see
Fixed-Target In-Path Rules.
Original Autodiscovery Process
The section describes how a client connects to a remote server when the SteelHeads have autodiscovery enabled. In this example, each SteelHead uses correct addressing and a single subnet.
Figure: Autodiscovery Process
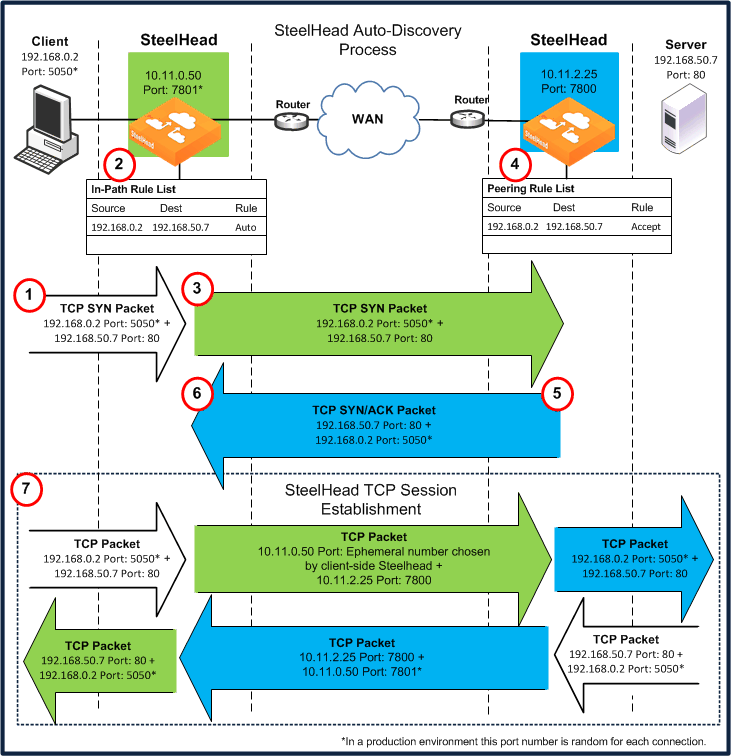
Note: This example does not show asymmetric routing detection or enhanced autodiscovery peering.
In the original autodiscovery process:
1. The client initiates the TCP connection by sending a TCP SYN packet.
2. The client-side SteelHead receives the packet on its LAN interface, examines the packet, discovers that it is a SYN, and continues processing the packet:
• Using information from the SYN packet (for example, the source or destination address, or VLAN tag), the SteelHead performs an action based on a configured set of rules, called in-path rules. In this example, because the matching rule for the packet is set to auto, the SteelHead uses autodiscovery to find the remote SteelHead.
• The SteelHead appends a TCP option to the packet TCP option field, which is called the probe query option. The probe query option contains the in-path IP address of the client-side SteelHead. Nothing else in the packet changes, only the option is added.
3. The SteelHead forwards the modified packet (denoted as SYN_probe_query) out of the WAN interface. Because neither the source nor destination fields are modified, the packet is routed in the same manner as if there was no SteelHead deployed.
4. The server-side SteelHead receives the SYN_probe_query packet on its WAN interface, examines the packet, discovers that it is a SYN packet, and searches for a TCP probe query. If found, the server-side SteelHead:
• uses the packet fields and the IP address of the client-side SteelHead to determine what action to take, based on its peering rules. In this example, because the matching rule is set to accept (or auto, depending on the RiOS version), the server-side SteelHead communicates to the client-side SteelHead that it is the remote optimization peer for this TCP connection.
• removes the probe_query option from the packet, and replaces it with a probe_response option (the probe_query and probe_response use the same TCP option number). The probe_response option contains the in-path IP address of the server-side SteelHead.
• reverses all of the source and destination fields (TCP and IP) in the packet header. The packet sequence numbers and flags are modified to make the packet look like a normal SYN/ACK server response packet.
If no server-side SteelHeads are present, the server ignores the TCP probe that was added by the client-side SteelHead, responds with a regular SYN/ACK resulting in a pass-through connection, and sends the SYN/ACK.
5. The server-side SteelHead transmits the packet to the client-side SteelHead. Because the destination IP address of the packet is now the client IP address, the packet is routed through the WAN just as if the server was responding to the client.
6. The client-side SteelHead receives the packet on its WAN interface, examines it, and discovers that it is a SYN/ACK. The client-side SteelHead scans for and finds the probe_response field and reads the in-path IP address of the server-side SteelHead. Now the client-side SteelHead knows all the parameters of the packet TCP flow, including the:
• IP addresses of the client and server.
• TCP source and destination ports for this connection.
• in-path IP address of the server-side SteelHead for this connection.
7. The SteelHeads establish three TCP connections:
• The client-side SteelHead completes the TCP connection setup with the client as if it were the server.
• The SteelHeads complete the TCP connection between each other.
• The server-side SteelHead completes the TCP connection with the server as if it were the client.
After the three TCP connections are established, optimization begins. The data sent between the client and server for this specific connection is optimized and carried on its own individual TCP connection between the SteelHeads.
Configuring Enhanced Autodiscovery
In RiOS 4.0.x or later, enhanced autodiscovery is available. Enhanced autodiscovery automatically discovers the last SteelHead in the network path of the TCP connection. In contrast, the original autodiscovery protocol automatically discovers the first SteelHead in the path. The difference is only seen in environments where there are three or more SteelHeads in the network path for connections to be optimized.
Enhanced autodiscovery works with SteelHeads running the original autodiscovery protocol. Enhanced autodiscovery ensures that a SteelHead optimizes only TCP connections that are being initiated or terminated at its local site, and it ensures that a SteelHead does not optimize traffic that is transiting through its site.
For information about passing through transit traffic using enhanced autodiscovery and peering rules, see
Configuring Pass-Through Transit Traffic.
To enable enhanced autodiscovery
• Connect to the SteelHead CLI and enter the following commands:
enable
configure terminal
in-path peering auto
Autodiscovery and Firewall Considerations
This section describes factors to consider when using autodiscovery:
Removal of the Riverbed TCP Option Probe
The most common reason that autodiscovery fails is because a device (typically security related) strips out the TCP options from optimized packets. Autodiscovery relies on using TCP options to determine if a remote SteelHead exists. Common devices that remove TCP options are firewalls and satellite routers.
The Riverbed Support site has knowledge base articles that show example configurations to allow Riverbed autodiscovery options through different firewall types.
To solve the problem, you can configure the devices to ignore or prevent stripping out the TCP option. Alternatively, you can use fixed-target rules on the SteelHeads to bypass the autodiscovery process.
Stateful Firewall Device in a Multiple In-Path Environment
Consider the following when you install a SteelHead in which a stateful firewall exists in a multiple in-path environment. A stateful firewall on the LAN side of a SteelHead might not detect the entire TCP handshake conversation, and this causes the firewall to drop packets.
Figure: Multiple In-Path Interfaces with Stateful Firewall on the LAN shows an example when the SteelHead is at a transit site where traffic passes through multiple interfaces on the SteelHead, with a firewall located on the LAN. The firewall does not see the whole TCP handshake.
Figure: Multiple In-Path Interfaces with Stateful Firewall on the LAN
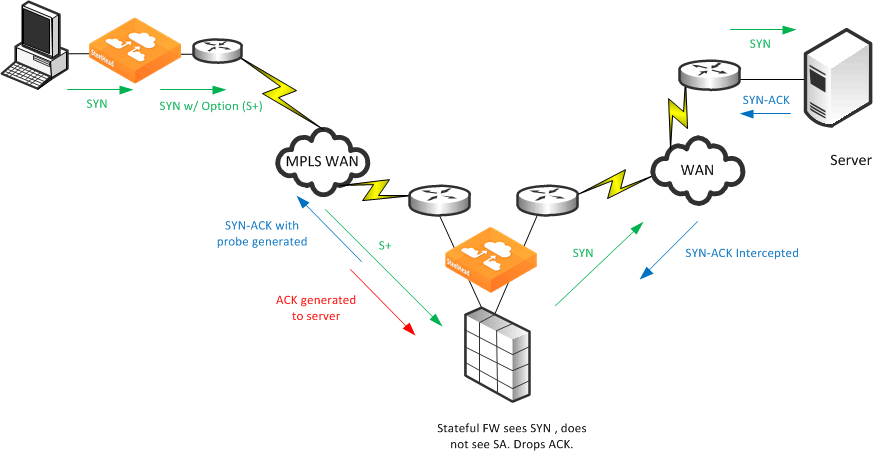
In this example, the stateful firewall detects the SYN packet to the server, but the SYN-ACK response from the server is intercepted at the SteelHead prior to reaching the firewall. When the server-side SteelHead originates the ACK to the server, the stateful firewall often denies the connection because it has not detected the proper SYN-ACK response.
Note: The SteelHead can appear to be bridging traffic between its in-path interfaces when it is not. The SteelHead always generates packets from the owner interface, but it intercepts packets on any in-path interface. This is behavior is necessary in asymmetric routing environments.
When you have a stateful firewall device in a multiple in-path environment, the goal of the SteelHead is to provide optimization for local traffic only at the transit site. The remote site usually has its own local SteelHead if optimization is required. To prevent the transit SteelHead from participating in the autodiscovery process, you can use peering rules to accept only probed SYNs destined to devices at the transit site. Contact Riverbed Professional Services for further options and solutions.
For more information about peering rules, see
Peering Rules.
Multiple In-Path Discovery Behavior
This section describes how multiple in-path interfaces on a SteelHead interact to intercept and originate packets for optimized connections. The SteelHead can support up to ten in-path interfaces, depending on the model. The packet flow is the same no matter how many interfaces are used.
You can use multiple in-path interfaces on a SteelHead to allow different network paths in an asymmetric routing environment. For example, you can have two or more routers that have circuits to the same or different MPLS circuits, and you can route traffic over either path.
Figure: Multiple In-Path Interface Example shows multiple in-path interfaces.
Figure: Multiple In-Path Interface Example

Figure: Multiple In-Path Interface Example shows traffic flowing to the server through a different router than traffic returning from the server. In many cases, you can use the two circuits for load balancing, so inbound or outbound traffic can legitimately flow through either router. In
Figure: Multiple In-Path Interface Example, the SteelHead on the right uses two in-path interfaces to allow for the possibility of asymmetric traffic.
The SteelHead intercepts packets for optimized connections on any in-path interface. The most common reason for enabling multiple in-path interfaces is to ensure that asymmetric routing does not prevent the SteelHead from detecting all packets for an optimized connection.
Packet origination from the SteelHead always comes from one in-path interface. Each of the optimizing SteelHeads has one in-path interface, which is referred to as the owner interface. The owner interface is bound to the optimized connection. On the client side, the first SteelHead's last in-path interface to detect the SYN packet from the client is the owner interface. The client-side SteelHead appends a TCP option to this SYN packet, known as a Riverbed probe.
If the SYN packet with a probe passes through the client-side SteelHead, the client-side SteelHead updates the IP address inside the probe option with the IP address of the in-path interface it is passing through. With original autodiscovery, the owner interface is the first in-path interface of the first server-side SteelHead. With enhanced autodiscovery, because the goal is to optimize to the last SteelHead in the path, the owner interface on the server side is the last SteelHead's first in-path interface to see the probed SYN. In most cases, the actual owner interface does not matter as much as which SteelHeads are performing the optimization.
Figure: Multiple In-Path Interface (More Detailed Example) shows a more detailed example of in-path interfaces. The server-side SteelHead is on the right.
Figure: Multiple In-Path Interface (More Detailed Example)
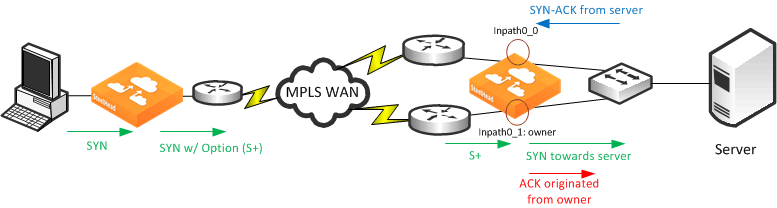
Figure: Multiple In-Path Interface (More Detailed Example) shows the client-side SteelHead owner interface is inpath0_0, because this interface detects the client SYN packet. The probed SYN packet reaches the server-side SteelHead on inpath0_1; therefore, inpath0_1 on the server-side SteelHead is the owner. The SteelHead intercepts packets for the optimized connections it is aware of. Even though the server SYN-ACK response comes back into inpath0_0, the SteelHead intercepts these packets and prevents asymmetric routing from bypassing the SteelHead. Packets originating from the SteelHead are always sourced from the owner interface. The ACK towards the server originates from the server-side SteelHead's inpath0_1 interface.
Controlling Optimization
You can configure what traffic a SteelHead optimizes and what other actions it performs, using the following rules:
• In-path rules - In-path rules determine the action a SteelHead takes when a connection is initiated, usually by a client.
• Peering rules - Peering rules determine how a SteelHead reacts when it detects a probe query.
This section includes the following topics:
In-Path Rules
In-path rules are used only when a connection is initiated. Because connections are typically initiated by clients, in-path rules are configured for the initiating, or client-side, SteelHead. In-path rules determine SteelHead behavior with SYN packets.
In-path rules are an ordered list of fields that a SteelHead attempts to match with SYN packet fields: for example, host label, port label, domain labels, source or destination subnet, IP address, VLAN, or TCP port. Each in-path rule has an action field. When a SteelHead finds a matching in-path rule for a SYN packet, the SteelHead treats the packet according to the action specified in the in-path rule.
RiOS 9.2 and later can use a preconfigured host, port, and domain label as a field identifier to intercept traffic. For more information on host and port labels for QoS and path selection, see
Application Definitions.
Note: Domain labels require both SteelHeads to be running RiOS 9.2 or later.
The in-path rule actions, each with different configuration possibilities, are as follows:
• Auto Discover - Uses the autodiscovery process to determine if a remote SteelHead is able to optimize the connection attempting to be created by this SYN packet.
• Fixed-Target - Omits the autodiscovery process and instead uses a specified remote SteelHead as an optimization peer. Fixed-target rules require the input of at least one remote target SteelHead; you can specify an optional backup SteelHead.
• Fixed-Target (Packet Mode Optimization) - Skips the autodiscovery process and uses a specified remote SteelHead as an optimization peer to perform bandwidth optimization on TCPv4, TCPv6, UDPv4, or UDPv6 connections.
• Pass Through - Allows the SYN packet to pass through the SteelHead. No optimization is performed on the TCP connection initiated by this SYN packet.
• Discard - Drops the SYN packet silently.
• Deny - Drops the SYN packet and sends a message back to its source.
Only use in-path rules in the following scenarios:
• TCP SYN packet arrives on the LAN interface of physical in-path deployments.
• TCP SYN packet arrives on the WAN interface of virtual in-path deployments.
Again, both of these scenarios are associated with the first, or initiating, SYN packet of the connection. In-path rules are applicable to only the client-side SteelHead. In-path rules have no effect on connections that are already established, regardless of whether the connections are being optimized.
In-path rule configurations differ depending on the action. For example, both the fixed-target and the autodiscovery actions allow you to choose configurations such as what type of optimization is applied, what type of data reduction is used, and what type of latency optimization is applied.
For an example of how in-path rules are used, see
Configuring High-Bandwidth, Low-Latency Environment.
Default In-Path Rules
The SteelHead ships with three default in-path rules. Default rules pass through certain types of traffic unoptimized because these protocols (Telnet, SSH, HTTPS) are typically used when you deploy and configure your SteelHeads. The default in-path rules can be removed or overwritten by altering or adding other rules to the in-path rule list, or by changing the port groups that are used. The default rules allow the following traffic to pass through the SteelHead without attempting optimization:
• Encrypted Traffic - Includes HTTPS, SSH, and others.
• Interactive Traffic - Includes Telnet, ICA, and others.
• Riverbed Protocols - Includes the TCP ports used by Riverbed products (that is, the SteelHead, the SteelHead Interceptor, and the Mobile Controller).
Peering Rules
Peering rules control SteelHead behavior when the appliance detects probe queries.
Peering rules (displayed using the show in-path peering rules command) are an ordered list of fields that a SteelHead uses to match with incoming SYN packet fields (for example, source or destination subnet, IP address, VLAN, or TCP port) and with the in-path IP address of the probing SteelHead. If more than one in-path interface exists on the probing SteelHead, apply one peering rule for each in-path interface. Peering rules are especially useful in complex networks.
Peering rule actions are as follows:
• Pass - The receiving SteelHead does not respond to the probing SteelHead, and it allows the SYN+probe packet to continue through the network.
• Accept - The receiving SteelHead responds to the probing SteelHead and becomes the remote-side SteelHead (that is, the peer SteelHead) for the optimized connection.
• Auto - If the receiving SteelHead is not using enhanced autodiscovery, this rule has the same effect as the Accept peering rule action. If enhanced autodiscovery is enabled, the SteelHead becomes the optimization peer only if it is the last SteelHead in the path to the server.
If a packet does not match any peering rule in the list, the default rule applies.
Kickoff and Automatic Kickoff Features
The kickoff feature provides you with a simple way to ensure that unoptimized active TCP connections passing through the SteelHead can be reset. When a connection is reset, it tries to reestablish itself using the SYN, SYN-ACK, ACK handshake. The SteelHead uses its in-path rule table to determine if the connection should be optimized.
For more information about in-path rules, see
In-Path Rules.
Connections can pass through a SteelHead unoptimized when they are set up and active before the SteelHead optimization service is running. By default, the SteelHead does not reset legacy connections and reports them as preexisting.
The main difference between the auto kickoff feature and the kickoff feature is that kickoff has a global setting that can affect all existing connections passing through a SteelHead. The global setting sends a reset to all connections, regardless of whether they need one. The global setting is not recommended for production networks, but you can use it in lab test scenarios. By default, this setting is not enabled. You can enable this setting in the Management Console or with the in-path kickoff command.
The automatic kickoff feature is included in RiOS 6.1 or later.
Figure: Automatic Kickoff Feature Global Setting
Note: You can reset individual connections manually on the SteelHead. This reset forces an existing connection from optimized to pass-through, or vice versa, when you test a new rule in the SteelHead's in-path rule table. You can also use manual reset for diagnostic purposes. You can set this feature on the Current Connections page in the Management Console or with the tcp connection send pass-reset command.
If you configure the automatic kickoff feature, when a SteelHead comes out of bypass mode, it automatically resets (by sending RST to the client and server) only the preexisting TCP connections that match in-path rules for which automatic kickoff is enabled.
If automatic kickoff and the global kickoff feature are both enabled on the same SteelHead, the global kickoff setting takes precedence.
One of the reasons to use the automatic kickoff feature instead of the kickoff feature is that you can enable it as part of an in-path rule for optimization (
Figure: Enable Automatic Kickoff). Automatic kickoff is only available for autodiscovery and fixed-target rules. When you enable automatic kickoff as part of an in-path rule, and the rule matches packet flow for a preexisting connection, the individual connection is reset automatically. Connections that are preexisting and do not match an in-path rule with automatic kickoff enabled are unaffected. If you add a new rule with automatic kickoff, any preexisting connection that matches the new rule is not affected until the next service restart.
Figure: Enable Automatic Kickoff
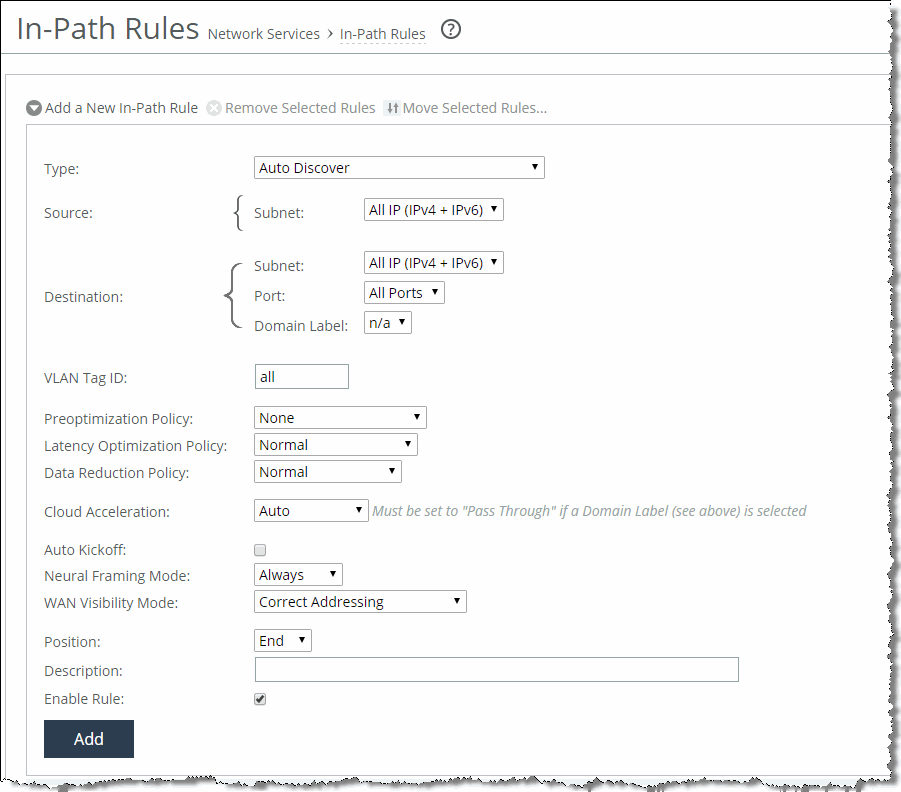
You use automatic kickoff primarily when you deploy SteelHeads in data protection environments. In data protection deployments, connections carrying the data replication traffic between the two storage arrays are often long-lived. This poses a problem if the connections are established as unoptimized or pass-through (for example, if the SteelHead is offline during connection setup), because the connections can remain unoptimized for a long time. Without the automatic kickoff on a SteelHead, you must manually intervene to reset the connections carrying data replication traffic on one of the storage arrays.
For more information about data protection deployment, see
Data Protection Deployments.
Although you can use automatic kickoff for any type of optimizable connection, the majority of connections for office applications—web, email, and so on—are comparatively short-lived and begin to be optimized after a brief period of time without any need for a reset.
When using the automatic kickoff feature, be aware of the following behaviors:
• Automatic kickoff does not have a timer.
A preexisting connection that remains inactive for a period of time is reset as soon as there is packet flow and it matches an in-path rule that has auto kickoff enabled. After the connection has been reset, an internal flag is set to prevent further kick offs for the connection unless the optimization service is restarted.
• Take note when you enable automatic kickoff to make sure you do not cause undesired behavior.
For example, in a design in which there is network asymmetry, if one or more SteelHead neighbors are configured and an in-path rule with automatic kickoff matches the connection, then the connection is kicked off even after detecting only one side of the handshake conversation.
For information about configuring the automatic kickoff feature, see the Riverbed Command-Line Interface Reference Manual and SteelHead Management Console User’s Guide.
Controlling Optimization Configuration Examples
The following examples show common deployment configurations:
Configuring High-Bandwidth, Low-Latency Environment
To show how in-path and peering rules might be used when designing SteelHead deployments, consider a network that has high bandwidth, low latency, and a large number of users.
Figure: High Bandwidth Utilization, Low Latency, and Many Connections Between SteelHeads shows this scenario occurring between two buildings at the same site. In this situation, you want to select SteelHead models to optimize traffic going to and from the WAN. However, you do not want to optimize traffic flowing between SteelHead A and SteelHead B.
Figure: High Bandwidth Utilization, Low Latency, and Many Connections Between SteelHeads
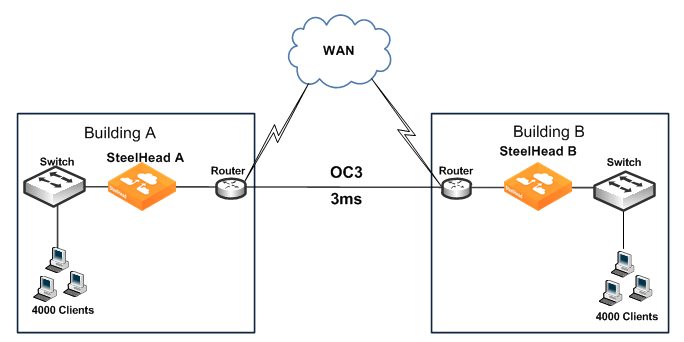
You can achieve this result as follows:
• In-path Rules - You can configure in-path rules on each of the SteelHeads (in Building A and Building B) so that the SteelHeads do not perform autodiscovery on any of the subnets in Building A and Building B. This option requires knowledge of all subnets within the two buildings, and it also requires that you update the list of subnets as the network is modified.
• Peering Rules - You can configure peering rules on SteelHead A and SteelHead B that pass through probe packets with in-path IP addresses of the other SteelHead (SteelHead A passes through probe packets with in-path IP addresses of SteelHead B, and vice versa). Using peering rules would require:
– less initial configuration.
– less ongoing maintenance, because you do not need to update the list of subnets in the list of peering rules for each of the SteelHeads.
Figure: Peering Rules for High Utilization Between SteelHeads shows how to use peering rules to prevent optimization from occurring between two SteelHeads and still allow optimization for traffic going to and from the WAN:
• SteelHead A has a Pass peering rule for all traffic coming from the SteelHead B in-path interface, so SteelHead A allows connections from SteelHead B to pass through it unoptimized.
• SteelHead B has a Pass peering rule for all traffic coming from the SteelHead A in-path interface, so SteelHead B allows connections from SteelHead A to pass through it unoptimized.
Figure: Peering Rules for High Utilization Between SteelHeads
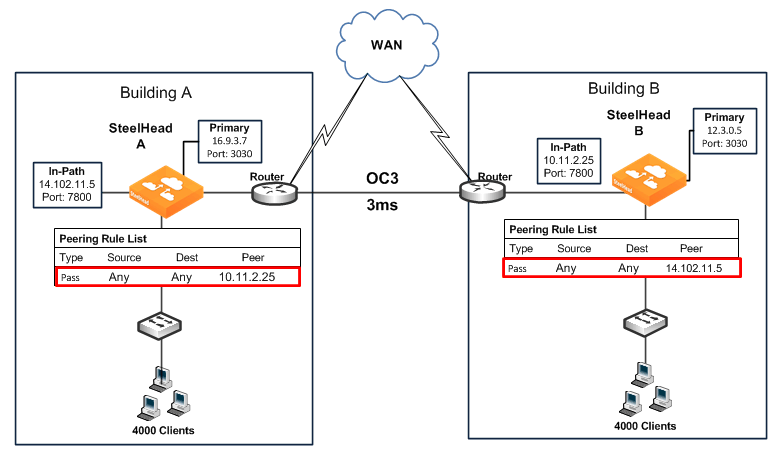
To configure a high-bandwidth, low-latency environment
1. On SteelHead A, connect to the CLI and enter the following commands:
enable
configure terminal
in-path peering rule pass peer 10.11.2.25 rulenum end
2. On SteelHead B, connect to the CLI and enter the following commands:
enable
configure terminal
in-path peering rule pass peer 14.102.11.5 rulenum end
If a packet does not apply to any of the configured peering rules, the auto-peering rule is used.
Configuring Pass-Through Transit Traffic
Transit traffic is data that is flowing through a SteelHead whose source or destination is not local to the SteelHead.
A SteelHead must optimize only traffic that is initiated or terminated at the site where it resides—any extra WAN hops between the SteelHead and the client or server greatly reduce the optimization benefits seen by those connections.
Figure: Transit Traffic shows the SteelHead at the Chicago site detects transit traffic to and from San Francisco and New York (traffic that is not initiated or terminated in Chicago). You want the initiating SteelHead (San Francisco) and the terminating SteelHead (New York) to optimize the connection. You do not want the SteelHead in Chicago to optimize the connection.
Figure: Transit Traffic
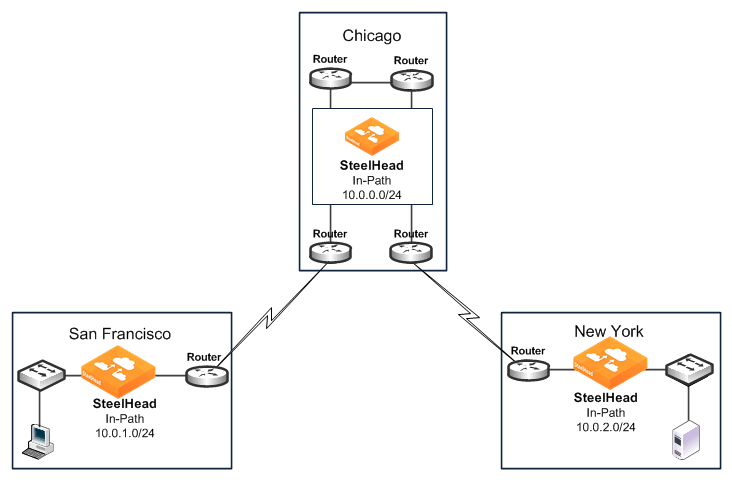
Figure: Transit Traffic shows the possible solutions to resolve this transit traffic issue. These points do not include the configuration for features such as duplex, alarms, and DNS. Also assume that the default in-path rules are configured on all three SteelHeads. Because the default action for in-path rules and peering rules is to use autodiscovery, two in-path and two peering rules must be configured on the Chicago SteelHead.
The following scenarios are possible solutions:
• Configure manual peering and in-path rules - Configure in-path and peering rules on the Chicago SteelHead to ignore transit traffic. You can configure peering rules for transit traffic by using the following commands:
enable
configure terminal
in-path rule auto srcaddr 10.0.0.0/24 rulenum end
in-path rule pass rulenum end
in-path peering rule auto dest 10.0.0.0/24 rulenum end
in-path peering rule pass rulenum end
Figure: Peering Rules for Transit Traffic
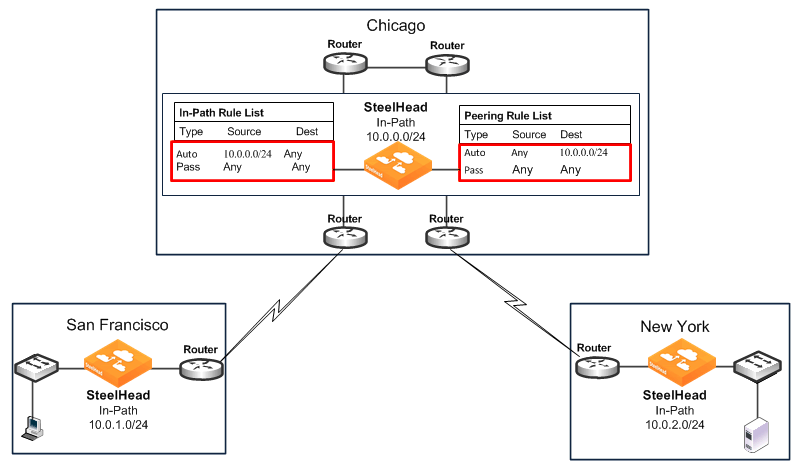
• Adjust network infrastructure - Relocate the Chicago SteelHead so that traffic initiated in San Francisco and destined for New York does not pass through the Chicago SteelHead. The Chicago SteelHead only detects traffic that is initiated or terminated at the Chicago site.
Figure: Resolving Transit Traffic by Adjusting Network Infrastructure shows relocating the Chicago SteelHead to detect only traffic that is initiated or terminated at the Chicago site.
Figure: Resolving Transit Traffic by Adjusting Network Infrastructure
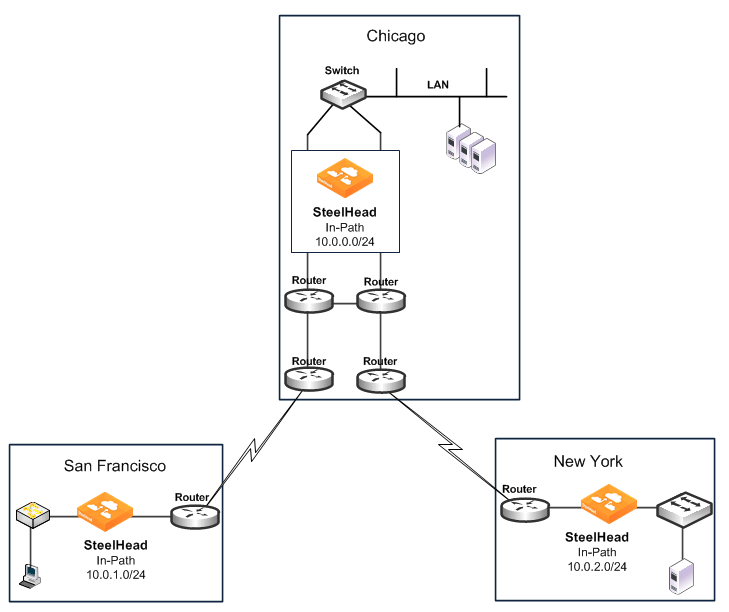
• Adjust traffic flow - Configure the two routers at the Chicago site to bypass the Chicago SteelHead.
Figure: Resolving Transit Traffic by Adjusting Traffic Flow shows the flow of traffic (initiated or terminated in San Francisco or New York) when the routers at the Chicago site are configured to bypass the Chicago SteelHead.
Figure: Resolving Transit Traffic by Adjusting Traffic Flow
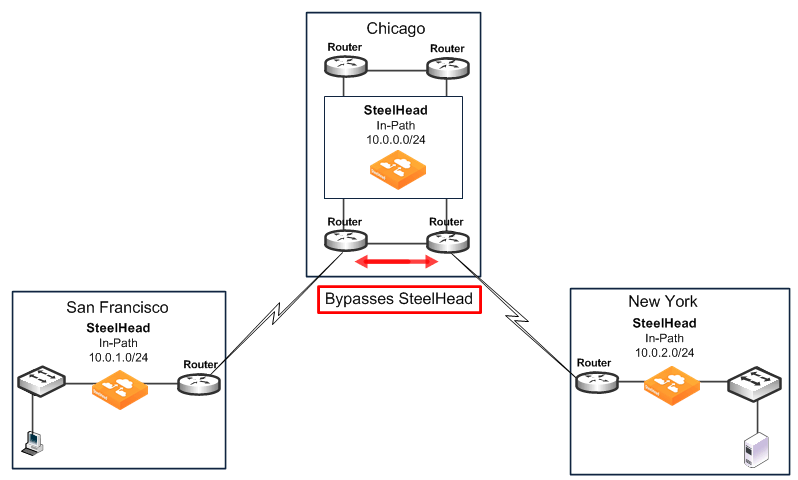
• Enable enhanced autodiscovery - Enable enhanced autodiscovery on all of the SteelHeads (in San Francisco, Chicago, and New York). Enhanced autodiscovery enables SteelHeads to automatically find the first and the last SteelHead that a given packet must traverse and ensures that a packet does not become transit traffic. This feature is available in RiOS 4.0.x or later. For information about enhanced autodiscovery, see
Configuring Enhanced Autodiscovery.
Fixed-Target In-Path Rules
A fixed-target in-path rule enables you to manually specify a remote SteelHead for optimization. As with all in-path rules, fixed-target in-path rules are executed only for SYN packets; therefore, they are configured on the initiating or client-side SteelHead. This section includes the following topics:
For information about in-path rules, see
In-Path Rules.
You can use fixed-target in-path rules in environments where the autodiscovery process cannot work.
A fixed-target rule requires the input of at least one target SteelHead; you can also specify an optional backup SteelHead.
Fixed-target in-path rules have several disadvantages compared to autodiscovery:
• You cannot easily determine which subnets to include in the fixed-target rule.
• Ongoing modifications to rules are needed as new subnets or SteelHeads are added to the network.
• Currently, you can specify two remote SteelHeads. All traffic is directed to the first SteelHead until it reaches capacity or until it stops responding to requests to connect. Traffic is then directed to the second SteelHead (until it reaches capacity or until it stops responding to requests to connect).
Note: Because of these disadvantages, fixed-target in-path rules are not as desirable as autodiscovery. In general, use fixed-target rules only when you cannot use autodiscovery.
LAN data flow has a significant difference depending on whether the fixed-target (or backup) IP address specified in the fixed-target in-path rule is for a SteelHead primary interface or its in-path interface.
Configuring a Fixed-Target In-Path Rule for an In-Path Deployment
In environments where the autodiscovery process does not work, use fixed-target in-path rules to target a remote in-path (physical or virtual) SteelHead. Configure the fixed-target in-path rule to target the remote SteelHead in-path interface.
Examples of environments where the autodiscovery process does not work are as follows:
• Traffic traversing the WAN passes through a satellite or other device that strips off TCP options, including those used by autodiscovery.
• Traffic traversing the WAN goes through a device that proxies TCP connections and uses its own TCP connection to transport the traffic. For example, some satellite-based WANs use built-in TCP proxies in their satellite uplinks.
When the target IP address of a fixed-target in-path rule is a SteelHead in-path interface, the traffic between the server-side SteelHead and the server looks like client-to-server traffic; that is, the server detects connections coming from the client IP address. This process is the same as when autodiscovery is used.
Figure: Fixed-Target In-Path Rule to the SteelHead In-Path Interface shows how to use a fixed-target in-path rule to the SteelHead in-path interface. This example uses a fixed-target in-path rule to resolve an issue with a satellite. The satellite gear strips the TCP option from the packet, which means the SteelHead does not detect the TCP option, and the connection cannot be optimized.
To enable the SteelHead to detect the TCP option, you configure a fixed-target in-path rule on the initiating SteelHead (SteelHead A) that targets the terminating SteelHead (SteelHead B) in-path interface.
Figure: Fixed-Target In-Path Rule to the SteelHead In-Path Interface
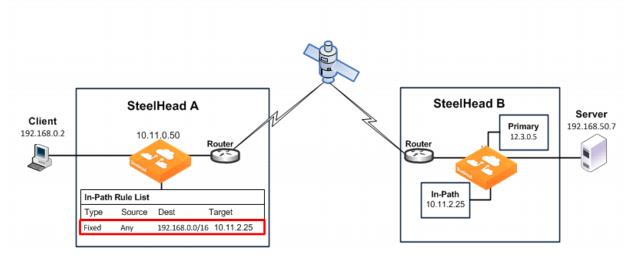
The fixed-target in-path rule specifies that only SYN packets destined for 192.168.0.0/16, SteelHead B subnets, are allowed through to the SteelHead B. All other packets are passed through the SteelHead.
You can configure in-path rules using the CLI.
To configure fixed-target in-path rule to an in-path address
• On SteelHead A, connect to the CLI and enter the following commands:
enable
configure terminal
in-path rule fixed-target target-addr 10.11.2.25 dstaddr 192.168.0.0/16 rulenum end
Fixed-Target In-Path Rule for an Out-of-Path Deployment
When you enable the remote SteelHead for out-of-path deployment, use fixed-target in-path rules to target the primary IP address. The most important caveat to this deployment method is that traffic to the remote server no longer uses the client IP address. Instead, the server detects connections coming to it from the out-of-path SteelHead primary IP address.
For deployment examples, see
Out-of-Path Deployments.
Best Practices for SteelHead Deployments
The following list represents best practices for deploying your SteelHeads. These best practices are not requirements, but Riverbed recommends that you follow these suggestions because they lead to designs that require the least amount of initial and ongoing configuration:
• Use in-path designs - Whenever possible, use a physical in-path deployment—the most common type of SteelHead deployment. Physical in-path deployments are easier to manage and configure than WCCP, PBR, and Layer-4 designs. In-path designs generally require no extra configuration on the connected routers or switches. If desired, you can limit traffic to be optimized on the SteelHead.
• Use the correct cables - To ensure that traffic flows not only when the SteelHead is optimizing traffic, but also when the SteelHead transitions to fail-to-wire mode, use the appropriate crossover or straight-through cable to connect the SteelHead to a router or switch. Verify the cable selection by removing power from the SteelHead and then test connectivity through it.
• Set matching duplex speeds - The most common cause of performance issues is duplex mismatch on the SteelHead WAN or LAN interfaces or on the interface of a device connected to the SteelHead. Most commonly, the issue is with the interface of a network device deployed prior to the SteelHead.
• Minimize the effect of link state transition - Use the Cisco spanning-tree portfast command on Cisco switches, or similar configuration options on your routers and switches, to minimize the amount of time an interface stops forwarding traffic when the SteelHead transitions to failure mode.
• Use serial rather than parallel designs - Parallel designs are physical in-path designs in which a SteelHead has some, but not all, of the WAN links passing through it, and other SteelHeads have the remaining WAN links passing through them. Connection forwarding must be configured for parallel designs. In general, it is easier to use physical in-path designs where one SteelHead has all of the links to the WAN passing through it.
• Do not optimize transit traffic - Ideally, SteelHeads optimize only traffic that is initiated or terminated at its local site. To avoid optimizing transit traffic, deploy the SteelHeads where the LAN connects to the WAN and not where LAN-to-LAN or WAN-to-WAN traffic can pass through (or be redirected to) the SteelHead.
• Position your SteelHeads close to your network endpoints - For optimal performance, minimize latency between SteelHeads and their respective clients and servers. By deploying SteelHeads as close as possible to your network endpoints (that is, place client-side SteelHeads as close to your clients as possible, and place server-side SteelHeads as close to your servers as possible).
• Use WAN visibility modes that interoperate with monitoring, QoS, and security infrastructure - RiOS currently supports four different WAN visibility modes, including granular control for their usage. This support ensures that the most appropriate mode is used.
• Use RiOS data store synchronization - Regardless of the deployment type or clustering used at a site, RiOS data store synchronization can allow significant bandwidth optimization, even after a SteelHead or hard drive failure.
• Use connection forwarding and allow-failure in a WCCP cluster - In a WCCP cluster, use connection forwarding and the
allow-failure command between SteelHeads. For details, see
Connection Forwarding.
• Avoid using fixed-target in-path rules - Use the autodiscovery feature whenever possible, thus avoiding the need to define fixed-target, in-path rules.
• Understand in-path rules versus peering rules - Use in-path rules to modify SteelHead behavior when a connection is initiated. Use peering rules to modify SteelHead behavior when it detects autodiscovery tagged packets.
• Use Riverbed Professional Services or an authorized Riverbed Partner - Training (both standard and custom) and consultation are available for small to large, and extra-large, deployments.
• Manually configure the primary interface in out-of-path deployments - You must manually configure the IP address for any optimization interface, including the primary interface, in an out-of-path deployment. DHCP is not supported.