Network Integration Tools
This chapter describes SteelHead tools that you can integrate with your network. This chapter includes the following sections:
Redundancy and Clustering
This section describes redundant deployment of SteelHeads in your network. Redundant deployment ensures that optimization continues in case of a SteelHead failure. Redundancy and clustering options are available for each type of deployment. This section includes the following topics:
Physical In-Path Deployments
The following redundancy options for physical in-path deployments are available:
• Primary and Backup In-Path Deployment - In a primary and backup deployment, two SteelHeads are placed in a physical in-path mode. One of the SteelHeads is configured as a primary, and the other is configured as the backup. The primary SteelHead (Riverbed recommends the SteelHead closest to the LAN) optimizes traffic, and the backup SteelHead constantly checks to make sure the primary SteelHead is functioning. If the backup SteelHead cannot reach the primary, or if the primary reaches maximum-connection-count capacity (called admission control), the backup SteelHead begins optimizing new connections until the primary returns to an operational state. After the primary has recovered, the backup SteelHead stops optimizing new connections and allows the primary to resume optimizing new connections. However, the backup SteelHead continues to optimize connections that were made while the primary was down. While the backup SteelHead should not intercept or optimize new connections in normal operation, Riverbed recommends that you configure peering rules on the SteelHeads to prevent them from choosing each other as optimization peers even in the event of a check failure. In a serial deployment, Riverbed recommends planning and using a primary and backup configuration over a serial cluster configuration.
• Serial Cluster In-Path Deployment - In a serial cluster deployment, two or more SteelHeads are placed in a physical in-path mode, and the SteelHeads concurrently optimize connections. Because the SteelHead closest to the LAN detects the combined LAN bandwidth of all of the SteelHeads in the series, serial clustering is supported on only the higher-end SteelHead models. Serial clustering requires configuring peering rules on the SteelHeads to prevent them from choosing each other as optimization peers.
In general, Riverbed recommends primary and backup deployments due to simplicity in troubleshooting and sizing planning. Serial clusters can be appropriate in specific environments in which different subsets of traffic are partitioned to each SteelHead.
Deployments that use connection forwarding with multiple SteelHeads, each covering different links to the WAN, do not necessarily provide redundancy.
Virtual In-Path Deployments
For virtual in-path deployments, the clustering and redundancy options vary depending on which redirection method is being used. WCCP, the most common virtual in-path deployment method, allows options like N+1 redundancy and 1+1 redundancy.
For information about virtual in-path deployments, see
Virtual In-Path Deployments.
Out-of-Path Deployments
For an out-of-path deployment, you can configure two SteelHeads (a primary and a backup), with fixed-target rules that specify traffic for optimization. If the primary SteelHead becomes unreachable, new connections are optimized by the backup SteelHead. If the backup SteelHead is down, no optimization occurs, and traffic is passed through the network unoptimized.
The primary SteelHead uses an out-of-band (OOB) connection. The OOB connection is a single, unique TCP connection that communicates internal information only; it does not contain optimized data. If the primary SteelHead becomes unavailable, it loses this OOB connection and the OOB connection times out in approximately 40 to 45 seconds. After the OOB connection times out, the client-side SteelHead declares the primary SteelHead unavailable and connects to the backup SteelHead.
During the 40- to 45-second delay before the client-side SteelHead declares a peer unavailable, it passes through any incoming new connections; they are not black holed.
Although the client-side SteelHead is using the backup SteelHead for optimization, it attempts to connect to the primary SteelHead every 30 seconds. If the connection succeeds, the client-side SteelHead reconnects to the primary SteelHead for any new connections. Existing connections remain on the backup SteelHead for their duration. Immediately after a recovery from a primary failure, connections are optimized by both the primary SteelHead and the backup.
If both the primary and backup SteelHeads become unreachable, the client-side SteelHead tries to connect to both appliances every 30 seconds. Any new connections are passed through the network unoptimized.
For information about out-of-path deployments, see
Out-of-Path Deployments.
Fail-to-Wire and Fail-to-Block
In physical in-path deployments, the SteelHead LAN and WAN ports that traffic flows through are internally connected by circuitry that can take special action in the event of a disk failure, a software crash, a runaway software process, or even loss of power to the SteelHead.
All SteelHead models and in-path network interface cards support fail-to-wire mode, where, in the event of a failure or loss of power, the LAN and WAN ports become internally connected as if they were the ends of a crossover cable, thereby providing uninterrupted transmission of data over the WAN. The default failure mode is fail-to-wire mode.

SteelHead-v supports fail-to-wire or fail-to-block only when deployed with a Riverbed NIC. For more details, see the
SteelHead (Virtual Edition) Installation Guide.
Certain in-path network interface cards also support a fail-to-block mode, where in the event of a failure or loss of power, the SteelHead LAN and WAN interfaces completely lose link status. When fail-to-block is enabled, a failed SteelHead blocks traffic along its path, forcing traffic to be rerouted onto other paths (where the remaining SteelHeads are deployed).
For information about fail-to-block mode, see
Fail-to-Block Mode. For information about SteelHead LAN and WAN ports and physical in-path deployments, see
Logical In-Path Interface. For information about physical in-path deployments, see
Physical In-Path Deployments.
Overview of Link State Propagation
In physical in-path deployments, link state propagation (LSP) can shorten the recovery time of a link failure. Link state propagation communicates link status between the devices connected to the SteelHead. When this feature is enabled, the link state of each SteelHead LAN-WAN pair is monitored. If either physical port loses link status, the other corresponding physical port brings its link down. Allowing link failure to quickly propagate through a chain of devices, LSP is useful in environments where link status is used for fast failure detection.
In RiOS 6.0 or later, link state propagation is enabled by default.

SteelHead-c models do not support LSP.
SteelHead-v running RiOS 8.0.3 with ESXi 5.0 and later using a Riverbed NIC card support LSP.
These SteelHead-v configurations do not support LSP:
• SteelHead-v models running ESX/ESXi 4.0 or 4.1
• SteelHead-v models running Microsoft Hyper-V
• SteelHead-v models running RiOS 8.0.2 and earlier
For information about physical in-path deployments, see
Physical In-Path Deployments. For more information about LSP, see
Configuring Link State Propagation.
Connection Forwarding
For a SteelHead to optimize a TCP connection, it must detect all of the packets for that connection. When you use connection forwarding, multiple SteelHeads work together and share information about which connections are being optimized by each. With connection forwarding, the LAN interface forwards and receives connection-forwarding packets. This section includes the following topics:
SteelHeads that are configured to use connection forwarding with each other are known as connection-forwarding neighbors. If a SteelHead detects a packet belonging to a connection that is optimized by a different SteelHead, it forwards it to the correct SteelHead. When a neighbor SteelHead reaches its optimization capacity, that SteelHead stops optimizing new connections but continues to forward packets for TCP connections being optimized by its neighbors.
You can use connection forwarding in both physical in-path deployments and virtual in-path deployments. In physical in-path deployments, connection forwarding is used between SteelHeads that are deployed on separate parallel paths to the WAN. In virtual in-path deployments, connection forwarding is used when the redirection mechanism does not guarantee that packets for a TCP connection are always sent to the same SteelHead. This includes the WCCP protocol, a commonly used virtual in-path deployment method.
Typically, it is easier to design physical in-path deployments that do not require connection forwarding. For example, if you have multiple paths to the WAN, you can use a SteelHead model that supports multiple in-path interfaces, instead of using multiple SteelHeads with single in-path interfaces. In general, serial deployments are preferred over parallel deployments.
For information about deployment best practices, see
Best Practices for SteelHead Deployments.
Figure: Connection Forwarding SteelHeads shows a site with multiple paths to the WAN. SteelHead A and SteelHead B can be configured as connection-forwarding neighbors. This configuration ensures that if a routing or switching change causes TCP connection packets to change paths, either SteelHead A or SteelHead B can forward the packets back to the correct SteelHead.
Figure: Connection Forwarding SteelHeads
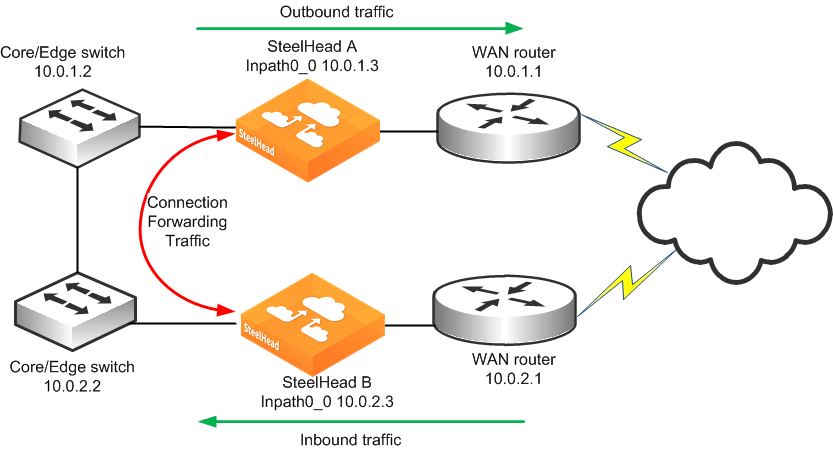
For information about connection forwarding and MTU sizing, see
Connection-Forwarding MTU Considerations.
Configuring Connection Forwarding
The following example is based on the assumption that the SteelHeads have already been configured properly for in-path interception.
To configure connection forwarding
1. On SteelHead A, connect to the CLI and enter the following commands:
enable
configure terminal
steelhead communication enable
steelhead name SteelHeadB main-ip 10.0.2.3
2. On SteelHead B, connect to the CLI and enter the following commands:
enable
configure terminal
steelhead communication enable
steelhead name SteelHeadA main-ip 10.0.1.3
When SteelHead A begins optimizing a new TCP connection, it communicates this activity to SteelHead B, provides the IP addresses and TCP port numbers for the new TCP connection, and defines a dynamic TCP port on which to forward packets.
If SteelHead B detects a packet that matches the connection, it takes the packet, alters its destination IP address to be the in-path IP address of SteelHead A, alters its destination TCP port to be the specific dynamic port that SteelHead A specified for the connection, and transmits the packet using its routing table.
In most environments, Riverbed recommends that you configure connection-forwarding SteelHeads to send traffic to each other through the LAN side of the network. Generally, the LAN-side network equipment is connected through low-latency network equipment with more than sufficient connectivity, and the WAN-side equipment might not be directly connected. To make sure that the connection-forwarding neighbor SteelHead sends traffic to each of their in-path IP addresses through the LAN, install a static route for the addresses whose next hop is the LAN gateway device.
For information about connection forwarding in multiple WAN routers, see
Configuring Basic Connection Forwarding.
Multiple-Interface Support Within Connection Forwarding
By default, SteelHeads communicate with neighbor appliances over a single in-path interface, on whatever is the lowest-numbered, enabled interface. If reachability is lost across the single interface, then the connection-forwarding capabilities are degraded or broken.
The steelhead communication multi-interface enable command allows all SteelHead neighbor in-path interface IP addresses to be visible to each peer. This visibility ensures neighbor communication if an interface fails. This command provides a level of interface redundancy; however, you can also think of the multiple-interface option as an improved version of the connection-forwarding protocol. Some additional features, such as the SteelHead Interceptor load-balancing functions, require you to enable multiple-interface support regardless of the number of interfaces enabled.
Connection-forwarding SteelHeads with multiple-interface support attempt to establish communication from every enabled in-path interface to every neighbor appliance in-path interface. Depending on traffic flow, you can forward optimized traffic between SteelHeads through any active in-path interfaces. Therefore, in typical environments, Riverbed recommends that all enabled and connected in-path interfaces on the SteelHeads be reachable by their connection-forwarding neighbors. Please consult Riverbed Professional Services or your account team for environments in which reachability between neighbor in-path interfaces is limited.
Tip: Riverbed recommends that you enable multiple-interface support in all new deployments using connection forwarding. You cannot combine connection-forwarding SteelHeads with multiple-interface support enabled with SteelHeads without the multiple-interface support enabled.
Failure Handling Within Connection Forwarding
By default, if a SteelHead loses connectivity to a connection-forwarding neighbor, the SteelHead stops attempting to optimize new connections. This behavior can be changed with the steelhead communication allow-failure command. If the allow-failure command is enabled, a SteelHead continues to optimize new connections, regardless of the state of its neighbors.
For virtual in-path deployments with multiple SteelHeads, including WCCP clusters, you must always use connection forwarding and the allow-failure command. Certain events, such as network failures and router or SteelHead cluster changes, can cause routers to change the destination SteelHead for TCP connection packets. When the destination changes, SteelHeads must be able to redirect traffic to each other to ensure that optimization continues.
For parallel physical in-path deployments, where multiple paths to the WAN are covered by different SteelHeads, connection forwarding is needed because packets for a TCP connection might be routed asymmetrically; that is, the packets for a connection might sometimes go through one path, and other times go through another path. The SteelHeads on these paths must use connection forwarding to ensure that the traffic for a TCP connection is always sent to the SteelHead that is performing optimization for that connection.
If the allow-failure command is used in a parallel physical in-path deployment, SteelHeads optimize only those connections that are routed through the paths with operating SteelHeads. TCP connections that are routed across paths without SteelHeads (or with a failed SteelHead) are detected by the asymmetric routing detection feature.
For physical in-path deployments, the allow-failure command is commonly used with the fail-to-block feature (on supported hardware). When fail-to-block is enabled, a failed SteelHead blocks traffic along its path, forcing traffic to be rerouted onto other paths (where the remaining SteelHeads are deployed).
You can configure your SteelHeads to automatically detect and report asymmetry within TCP connections as seen by the SteelHead. Asymmetric route auto-detection does not solve asymmetry; it simply detects and reports it and passes the asymmetric traffic unoptimized. For information about enabling asymmetric route auto-detection, see the SteelHead Management Console User’s Guide.
Connection-Forwarding Neighbor Latency
In general, Riverbed recommends that the maximum round-trip latency between connection forwarding SteelHeads is less than one millisecond.
You can deploy SteelHeads so that moderate latency exists between connection forwarding SteelHeads. Latency has an impact on the optimized traffic because each optimized connection requires communication between all connection forwarding SteelHead neighbors in order to share state about recognizing flows for redirection.
The longest round-trip latency between any two connection forwarding SteelHeads should be less than one-fifth of the round-trip latency to the closest optimized remote site. This precaution ensures that connection forwarding communication does not cause the connection setup time to be greater for optimized connections compared to unoptimized connections for the closest remote site. Deployments with round-trip latencies higher than 10 milliseconds between connection forwarding SteelHeads should only be implemented after a technical consultation with Riverbed.
For more details, see the SteelHead Management Console User’s Guide.
Overview of Simplified Routing
Simplified routing avoids situations when a packet traverses a SteelHead more than once—this behavior is called packet ricochet. In environments where the SteelHead is installed in a subnet different than the clients and servers, simplified routing prevents packet ricochet for optimized traffic from the SteelHead.
Figure: Packet Ricochet When the SteelHead Default Gateway Is on the WAN shows an example of packet ricochet when the SteelHead default gateway is configured for the WAN router, the host sits on a different network than the SteelHead, and simplified routing is not enabled.
Figure: Packet Ricochet When the SteelHead Default Gateway Is on the WAN
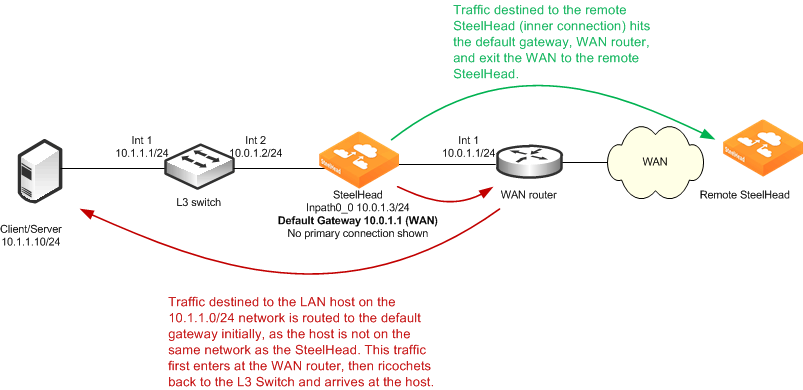
Figure: Packet Ricochet When the SteelHead Default Gateway Is on the LAN shows a similar packet ricochet scenario, but with the default gateway of the SteelHead pointed to the LAN L3 switch.
Figure: Packet Ricochet When the SteelHead Default Gateway Is on the LAN
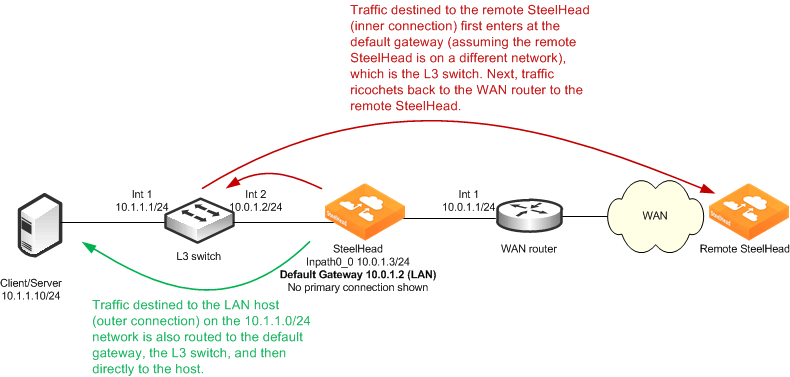
In both
Figure: Packet Ricochet When the SteelHead Default Gateway Is on the WAN and
Figure: Packet Ricochet When the SteelHead Default Gateway Is on the LAN, packets for some traffic take a suboptimal first hop from the SteelHead. While the detrimental effects of an extra hop are typically minor, packet ricochet causes problems in the following environments:
• Some environments that include firewalls or routers with ACLs might not permit traffic to ricochet or traverse back out the same interface as it came in.
• Some monitoring tools that rely on NetFlow or SNMP data count the ricocheted traffic as additional traffic.
• Packet ricochet causes the adjacent network devices to perform unnecessary work.
The packet ricochet scenarios only occur in physically in-path environments where the SteelHead is installed in a subnet different than the clients or servers. In these environments, you can avoid packet ricochet by either configuring static routes or by using simplified routing.
For example,
Figure: Packet Ricochet When the SteelHead Default Gateway Is on the WAN shows you can configure a static route for the host network, 10.1.1.0/24 to point directly to the 10.0.1.2 L3 switch, preventing this traffic from using the default gateway. However, the static route method often becomes administratively burdensome, especially in larger or complex LAN environments.
Simplified routing resolves packet ricochet, without using static routes or routing protocols, by building an IP to next-hop MAC address mapping learned from received packets. The SteelHead learns the correct MAC address by examining the packet's destination or source IP and MAC address.
Using
Figure: Packet Ricochet When the SteelHead Default Gateway Is on the WAN as an example, assume simplified routing is enabled. If an autodiscovery packet arrives from the WAN to the 10.1.1.10 host, the SteelHead detects the packet with the destination IP of 10.1.1.10 along with the destination MAC of the L3 switch, and it records the IP with associated MAC in its simplified routing table—also referred to as the
macmap table. Whenever the SteelHead generates traffic destined to the 10.1.1.10 host, it uses the associated MAC of the L3 switch instead of the default gateway. This behavior avoids the packet ricochet.
Only use simplified routing for optimized traffic generated by the SteelHead, not pass-through traffic. For pass-through traffic, the SteelHead sends the packets out the opposite WAN or LAN interface as it came in. You can also use simplified routing when the destination IP is on a different subnet than the SteelHead in-path IP. If the destination IP resides on the same network, the SteelHead uses ARP for the correct MAC address. When the destination IP resides on a different network, then a simplified routing entry (if recorded) takes precedence over the default gateway, or by default, any configured static routes. To override the default behavior and have the static routes take precedence over simplified routing, use the in-path simplified mac-def-gw-only command.
Simplified routing plays an important role in maintaining VLAN ID when transmitting across the WAN when the SteelHead is deployed on an 802.1Q trunk and using the full address transparency WAN visibility mode.
For more information about simplified routing in physical in-path deployments, see
Configuring Simplified Routing.