Troubleshooting SteelHead Deployment Problems
This chapter describes common deployment problems and solutions. This chapter includes the following sections:
For information about SteelHead installation issues, see the SteelHead Installation and Configuration Guide.
For information about the factors to consider before you deploy the SteelHead, see
Choosing the Right SteelHead Model.
Common Deployment Issues
This section provides solutions to the following deployment issues:
Duplex Mismatches
This section describes common problems that can occur in networks in which duplex settings do not match. Duplex mismatch occurs when the speed of a network interface that is connected to the SteelHead does not match.
The number one cause of poor performance issues with SteelHead installations is duplex mismatch. A duplex mismatch can cause performance degradation and packet loss.
Signs of duplex mismatch:
• You cannot connect to an attached device.
• You can connect with a device when you choose auto-negotiation, but you cannot connect with the same device when you manually set the speed or duplex.
• Minimal or no performance gains.
• Loss of network connectivity.
• Intermittent application or file errors.
• All of your applications are slower after you have installed in-path SteelHeads.
To determine whether the slowness is caused by a duplex mismatch
1. Create a pass-through rule for the application on the client-side SteelHead and ensure that the rule is at the top of the in-path rules list. You add a pass‑through rule with the in-path rule pass-through command, or you can use the Management Console.
2. Restart the application.
3. Check that all connections related to the application are being passed through. If all connections related to the application are being passed through and the performance of the application does not return to the original levels, the slowness is most likely due to duplex mismatch.
The following sections describe several possible solutions to duplex mismatch.
Solution: Manually Set Matching Speed and Duplex
One solution for mismatched speed and duplex settings is to manually configure the settings.
1. Manually set (that is, hard set) matching speed and the duplex settings for the following four ports:
• Devices (switches) connected on the SteelHead LAN port
• Devices (routers) connected on the SteelHead WAN port
• The SteelHead LAN port
• The SteelHead WAN port
Riverbed recommends the following speeds:
• Fast Ethernet Interfaces: 100 megabits full duplex
• Gigabit Interfaces: 1000 megabits full duplex
Riverbed recommends that you avoid using half-duplex mode whenever possible. If you are using a modern interface, and it appears to not support full duplex, double check the duplex setting. It is likely that one side is set to auto and the other is set to fixed. To manually change interface speed and duplex settings, use the interface command. For details, see the Riverbed Command-Line Interface Reference Manual.
2. Verify that each of the above devices:
• have settings that match in optimizing mode.
• is configured to see interface speed and duplex settings, using the show configuration command. By default, the SteelHead automatically negotiates speed and duplex mode for all data rates and supports full duplex mode and flow control. To change interface speed and duplex settings, use the interface command.
• have settings that match in bypass mode.
• are not showing any errors or collisions.
• does not have a half-duplex configuration (forced or negotiated) on either the WAN or the LAN.
• has at least 100 Mbps speed, forced or negotiated, on the LAN.
• has network connectivity in optimization and in failure mode.
3. Test connectivity with the SteelHead powered off to ensure that the SteelHead does not sever the network in the event of a hardware or software problem. This must be done last, especially after making any duplex changes on the connected devices.
4. If the SteelHead is powered off and you cannot pass traffic through it, verify that you are using the correct cables for all devices connected to the SteelHead. The type of cable is determined by the device connecting to the SteelHead:
• Router to SteelHead: use a crossover cable.
• Switch to SteelHead: use a straight-through cable.
• Do not rely on Auto MDI/MDI-X to determine which cables you are using.
5. Use a cable tester to verify that the SteelHead in-path interface is functioning properly: turn off the SteelHead, and connect the cable tester to the LAN and WAN port. The test result must show a crossover connection.
6. Use a cable tester to verify that all of the cables connected to the SteelHead are functioning properly.
For information about how to choose the correct cables, see
Choosing the Correct Cables.
Solution: Use an Intermediary Switch
If you have tried to manually set matching speed and duplex settings, and duplex mismatch still causes slow performance and lost packets after you deploy in-path SteelHeads, introduce an intermediary switch that is more compatible with both existing network interfaces. Riverbed recommends that you use this option only as a last option.
Important: To use an intermediary switch, you must also change your network cables appropriately.
Network Asymmetry
If some of the connections in a network are optimized and some are passed through unoptimized, it might be due to network asymmetry. Network asymmetry causes a client request to traverse a different network path than the server response. Network asymmetry can also break connections.
If SYN packets that traverse from one side of the network are optimized, but SYN packets that traverse from the opposite side of the network are passed-through unoptimized, it is a symptom of network asymmetry.
Figure: Server-Side Asymmetric Network shows an asymmetric server-side network in which a server response can traverse a path (the bottom path) in which a SteelHead is not installed.
Figure: Server-Side Asymmetric Network
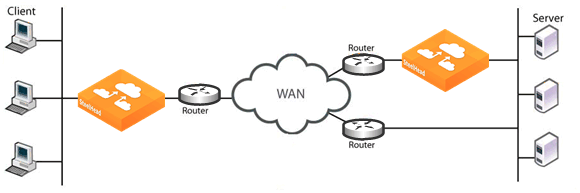
The following sections describe several possible solutions to network asymmetry.
With RiOS v3.0.x or later, you can configure your SteelHeads to automatically detect and report asymmetric routes within your network. Whether asymmetric routing is automatically detected by SteelHeads or is detected in some other way, use the solutions described in the following sections to work around it.
For information about configuring auto-detection of asymmetric routes, see the SteelHead Management Console User’s Guide.
Solution: Use Connection Forwarding
For a network connection to be optimized, packets traveling in both network directions (from server to client and from client to server) must pass through the same client-side and server-side SteelHead. In networks in which asymmetric routing occurs because client requests or server responses can traverse different paths, you can solve it by:
• ensuring that there is a SteelHead installed on every possible path a packet can traverse. You would install a second server-side SteelHead, covering the bottom path. For details, see
Figure: Server-Side Asymmetric Network.
• setting up connection forwarding to route packets that traversed one SteelHead in one direction to traverse the same SteelHead in the opposite direction. Connection forwarding can be configured on the client-side or server-side of a network.
To set up connection forwarding, use the Management Console or CLI as described in the SteelHead Management Console User’s Guide and the Riverbed Command-Line Interface Reference Manual.
For more information, see
Connection Forwarding.
Solution: Use Virtual In-Path Deployment
Because a connection cannot be optimized unless packets traveling in both network directions pass through the same client-side SteelHead and the same server-side SteelHead, you can use a virtual in-path deployment to solve network asymmetry.
In the example network shown in
Figure: Server-Side Asymmetric Network, changing the server-side SteelHead that is deployed in-path on the top server-side path to a virtual in-path deployment, ensures that all server-side traffic passes through the server-side SteelHead.
Figure: Virtual In-Path Deployment to Solve Network Asymmetry
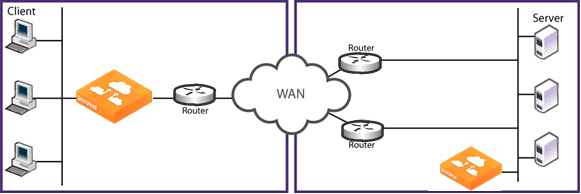
A virtual in-path deployment differs from a physical in-path deployment in that a packet redirection mechanism directs packets to SteelHeads that are not in the physical path of the client or server. Redirection mechanisms include a Layer-4 switch (or server load balancer), WCCP, and PBR. These redirection mechanisms are described in:
Solution: Deploy a Four-Port SteelHead
If you have a SteelHead that supports a Four-Port Copper Gigabit-Ethernet PCI-X card, you can deploy it to solve network asymmetry in which a two-port SteelHead or one of the solutions described in the previous sections is not successful.
For example, instead of the two-port SteelHead deployed to one server-side path as shown
Figure: Server-Side Asymmetric Network, you deploy a four-port SteelHead on the server-side of the network. All server-side traffic passes through the four-port SteelHead and asymmetric routing is eliminated.
For information about two-port and four-port SteelHeads, see the Network and Storage Card Installation Guide.
Unknown (or Unwanted) SteelHead Appears on the Current Connections List
Enhanced autodiscovery greatly reduces the complexities and time it takes to deploy SteelHeads. It works so seamlessly that occasionally it has the undesirable effect of peering with SteelHeads on the internet that are not in your organization's management domain or your corporate business unit. When an unknown (or unwanted) SteelHead appears connected to your network, you can create a peering rule to prevent it from peering and remove it from your list of peers. The peering rule defines what to do when a SteelHead receives an autodiscovery probe from the unknown SteelHead.
To prevent an unknown SteelHead from peering
1. Choose Configure > Optimization > Peering Rules.
2. Click Add a New Peering Rule.
3. Select Passthrough as the rule type.
4. Specify the source and destination subnets. The source subnet is the remote location network subnet (in the format XXX.XXX.XXX.XXX/XX). The destination subnet is your local network subnet (in the format XXX.XXX.XXX.XXX/XX).
5. Click Add.
In this example, the peering rule passes through traffic from the unknown SteelHead in the remote location.
When you use this method and add a new remote location in the future, you must create a new peering rule that accepts traffic from the remote location. Place this new Accept rule before the Pass-through rule.
If you do not know the network subnet for the remote location, there is another option: you can create a peering rule that allows peering from your corporate network subnet and denies it otherwise. For example, create a peering rule that accepts peering from your corporate network subnet and place it as the first rule in the list.
Next, create a second peering rule to pass through all other traffic. In this example, when the local SteelHead receives an autodiscovery probe, it checks the peering rules first (from top to bottom). If it matches the first Accept rule, the local SteelHead peers with the other SteelHead. If it does not match the first Accept rule, the local SteelHead checks the next peering rule, which is the pass-through rule for all other traffic. In this case, the local SteelHead just passes through the traffic and does not peer with the other SteelHead.
After you add the peering rule, the unknown SteelHead appliance appears in the Current Connections report as a Connected Appliance until the connection times out. After the connection becomes inactive, it appears dimmed. To remove the unknown appliance completely, restart the optimization service.
Outdated Antivirus Software
After installing SteelHeads, if application access over the network does not speed up or certain operations on files (such as dragging and dropping) speed up greatly but application access does not, it might be due to old antivirus software installed on a network client.
For similar problems, see:
Solution: Upgrade Antivirus Software
If it is safe to do so, temporarily disable the antivirus software and try opening files. If performance improves with antivirus software disabled, Riverbed recommends that you upgrade the antivirus software.
If performance does not improve with antivirus software disabled or after upgrading antivirus software, contact Riverbed Support site at
https://support.riverbed.com.
Packet Ricochets
Signs of packet ricochet are:
• Network connections fail on their first attempt but succeed on subsequent attempts.
• The SteelHead on one or both sides of a network has an in-path interface that is different from that of the local host.
• You have not defined any in-path routes in your network.
• Connections between the SteelHead and the clients or server are routed through the WAN interface to a WAN gateway, and then they are routed through a SteelHead to the next-hop LAN gateway.
• The WAN router drops SYN packets from the SteelHead before it issues an ICMP redirect.
Solution: Add In-Path Routes
To prevent packet ricochet, add in-path routes to local destinations. For details, see SteelHead Management Console User’s Guide.
For information about packet ricochet, see
In-Path Redundancy and Clustering Examples.
Solution: Use Simplified Routing
You can also use simplified routing to prevent packet ricochet. To configure simplified routing, use
the in-path simplified routing command or the Management Console.
For information about simplified routing and how to configure it, see the Riverbed Command-Line Interface Reference Manual or the SteelHead Management Console User’s Guide.
Router CPU Spikes After WCCP Configuration
If the CPU usage of the router spikes after WCCP configuration, it might be because you are not using a WCCP‑compatible Cisco IOS release or because you must use inbound redirection.
The following sections describe several possible solutions to router CPU spike after WCCP configuration.
Solution: Use Mask Assignment instead of Hash Assignment
The major difference between the hash and mask assignment methods lies in the way traffic is processed within the router/switch. With a mask assignment, traffic is processed entirely in the hardware, which means the CPU of the switch is minimal. A hash assignment uses the switch CPU for part of the load distribution calculation and hence places a significant load on the switch CPU. The mask assignment method was specifically designed for hardware-based switches and routers (such as Cisco 3560, 3750, 4500, 6500, and 7600).
For information about mask assignment, see
WCCP Virtual In-Path Deployments.
Solution: Check Internetwork Operating System Compatibility
Because WCCP is not fully integrated in every IOS release and on every platform, ensure that you are running a WCCP-compatible IOS release. If you have questions about the WCCP compatibility of your IOS release, contact Riverbed Support site at
https://support.riverbed.com.
If you are certain that you are running a WCCP-compatible IOS release and you experience router CPU spike after WCCP configuration, review the remaining sections for possible solutions.
Solution: Use Inbound Redirection
One possible solution to router CPU spike after WCCP configuration is to use inbound redirection instead of outbound redirection. Inbound redirection ensures that the router does not waste CPU cycles consulting the routing table before handling the traffic for WCCP redirection.
For information about redirection, see
WCCP Virtual In-Path DeploymentsSolution: Use Inbound Redirection with Fixed-Target Rules
If inbound redirection, as described in
Solution: Use Inbound Redirection, does not solve router CPU spike after WCCP is configured, try using inbound redirection with a fixed-target rule between SteelHeads. The fixed-target rule can eliminate one redirection interface.
Fixed-target rules directly specify server-side SteelHeads near the target server that you want to optimize. You determine which servers you would like the SteelHead to optimize (and, optionally, which ports), and you add fixed-target rules to specify the network of servers, ports, and out-of-path SteelHeads to use.
For information about how to configure inbound redirection and fixed-target rules, see
WCCP Virtual In-Path DeploymentsSolution: Use Inbound Redirection with Fixed-Target Rules and Redirect List
If the solutions described in the previous sections do not solve router CPU spike after WCCP is configured, try using inbound redirection with a fixed-target rule and a redirect list. A redirect list can reduce the load on the router by limiting the amount of unnecessary traffic that is redirected by the router.
Solution: Base Redirection on Ports Rather than ACLs
If the solutions described in the previous sections do not solve router CPU spike after WCCP configuration, consider basing traffic redirection on specific port numbers rather than using ACLs.
Solution: Use PBR
If the solutions described in the previous sections do not solve router CPU spike after WCCP configuration, consider using PBR instead of WCCP.
Server Message Block Signed Sessions
This section provides a brief overview of problems that can occur with Windows Server Message Block (SMB) signing. For information about SMB signing, the performance cost associated with it, and solutions to it, see the SteelHead Management Console User’s Guide.
If network connections appear to be optimized but there is no performance difference between a cold and warm transfer, it might be due to SMB-signed sessions.
SMB-signed sessions support compression and RiOS SDR, but render latency optimization (for example read-ahead, and write‑behind) unavailable.
Signs of SMB signing:
• Access to some Windows file servers across a WAN is slower than access to other Windows file servers across the WAN.
• Connections are shown as optimized in the Management Console.
• The results of a TCP dump show low WAN utilization for files where their contents do not match existing segments in the segment store.
• Copying files via FTP from the slow server is much faster than copying the same files via mapped network drives (CIFS).
When copying FTP from a slow server is much faster than copying from the same server via a mapped network drive, the possibility of other network problems (such as duplex mismatch or network congestion) with the server is ruled out.
• Log messages in the Management Console such as:
error=SMB_SHUTDOWN_ERR_SEC_SIG_ENABLED
The following sections describe possible solutions to SMB-signed sessions.
For similar problems, see:
Solution: Fully Optimize SMB-Signed Traffic
Before you use any of the following solutions, configure your SteelHead to optimize SMB-signed traffic. For information about how to configure SMB-signed traffic, see the SteelHead Deployment Guide - Protocols.
If you do not have the privileges or the correct information for SMB-signed traffic optimization, try the following solutions.
Solution: Enable Secure-CIFS
Enable Secure-CIFS using the protocol cifs secure-sig-opt enable command.
The Secure-CIFS feature automatically stops Windows SMB signing. SMB signing prevents the SteelHead from applying full optimization on CIFS connections and significantly reduces the performance gain from a SteelHead deployment. SMB-signed sessions support compression and RiOS SDR, but render latency optimization (read-ahead, write-behind) unavailable.
With Secure-CIFS enabled, you must consider the following factors:
• If the client-side machine has Required signing, enabling the Secure-CIFS feature prevents the client from connecting to the server.
• If the server-side machine has Required signing, the client and the server connect but you cannot perform full latency optimization with the SteelHead. (Domain Controllers default to Required.)
For information about SMB signing, see the SteelHead Installation and Configuration Guide.
Alternatively, if your deployment requires SMB signing, you can optimize signed CIFS messages by selecting Enable SMB Signing in the Optimization > Protocols: CIFS (SMB1) page of the Management Console. Before you enable SMB signing, make sure you disable Optimize Connections with Security Signatures. For detailed information about optimizing signed CIFS messages, including procedures for your Windows server, see the SteelHead Management Console User’s Guide.
Note: Secure-CIFS is enabled by default beginning with RiOS v2.x.
For details, see the SteelHead Management Console Online Help or the SteelHead Management Console User’s Guide.
Solution: Disable SMB Signing with Active Directory
If you have tried enabling Secure-CIFS as described in
Solution: Enable Secure-CIFS but SMB signing still occurs, consider using Active Directory (AD) to disable SMB signing requirements on servers or clients.
If the Security Signature feature does not disable SMB signing, you must revise the default SMB registry parameters. SMB signing is controlled by the following registry parameters:
enablesecuritysignature (SSEn)
requiresecuritysignature (SSReq)
The registry settings are located in:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\lanmanserver\parameters
The following table summarizes the default SMB signing registry parameters.
Machine Role | SSEn | SSReq |
Client/Workstation | ON | OFF |
Member Server | OFF | OFF |
Domain Controller | ON | ON |
With these default registry parameters, SMB signing is negotiated in the following manner:
• SMB/CIFS exchanges between the Client/Workstation and the Member Server are not signed.
• SMB/CIFS exchanges between the Client/Workstation and the Domain Controller are always signed.
The following table lists the complete matrix for SMB registry parameters that ensure full optimization (that is, bandwidth and latency optimization) using the SteelHead.
Number | Parameters on Workstation | Parameters on Server | Result |
SSReq | SSEn | SSReq | SSEn |
1 | OFF | OFF | OFF | OFF | Signature Disabled: SteelHead full optimization |
2 | OFF | OFF | OFF | ON | Signature Disabled: SteelHead full optimization |
3 | OFF | OFF | ON | ON | Cannot establish session |
4* | OFF | OFF | ON | ON | Cannot establish session |
5 | OFF | ON | OFF | OFF | Signature Disabled: SteelHead full optimization |
6 | OFF | ON | OFF | ON | Signature Enabled; SteelHead bandwidth optimization |
7 | OFF | ON | ON | ON | Signature Enabled; SteelHead bandwidth optimization |
8* | OFF | ON | OFF | ON | Signature Enabled; SteelHead bandwidth optimization |
9 | ON | ON | OFF | OFF | Cannot establish session |
10* | ON | ON | OFF | ON | Signature Enabled; SteelHead bandwidth optimization |
11 | ON | ON | ON | ON | Signature Enabled; SteelHead bandwidth optimization |
12 | ON | ON | OFF | ON | Signature Enabled; SteelHead bandwidth optimization |
13+ | ON | OFF | OFF | OFF | Cannot establish session |
14+ | ON | OFF | OFF | ON | Signature Enabled; SteelHead bandwidth optimization |
15+ | ON | OFF | ON | ON | Signature Enabled; SteelHead bandwidth optimization |
16+ | ON | OFF | OFF | ON | Signature Enabled; SteelHead bandwidth optimization |
Note: Rows with an asterisk (*) and a plus sign (+) are illegal combinations of SSReq and SSen on the server and the workstation respectively.
This table represents behavior for Windows 2000 workstations and servers with service pack 3 and Critical Fix Q329170. Prior to the critical fix, the security signature feature was not enabled or enforced even on domain controllers.
Each computer has the following set of parameters: one set for the computer as a server and the other set for the computer as a client.
Note: On the client, if SMB signing is set to Required, do not disable it on the server. For the best performance, enable the clients, disable the file servers, and enable domain controllers.
The following procedures assume that you have installed and configured the SteelHeads in your network.
To disable SMB signing on Windows 2000 Domain Controllers, member servers, and clients
1. Open Active Directory Users and Computers on the Domain Controller.
2. Right-click Domain Controllers and select Properties.
3. Select the Group Policy tab.
4. Select Default Domain Controllers Policy and click Edit.
5. Select Default Domain Controllers Policy/Computer Configuration/Windows Settings/Security Settings/Local Policies/Security Options.
6. Disable Digitally sign client communication (always) and Digitally sign server communication (always).
7. Disable Digitally sign client communication (when possible) and Digitally sign server communication (when possible).
8. Reboot all the Domain Controllers and member servers that you want to optimize.
Tip: You can also open a command prompt and enter gpupdate.exe /Force that forces the group policy you just modified to become active without rebooting.
You can verify that SMB signing has been disabled on your domain controllers, member servers, and clients. The following procedures assume that you have installed and configured the SteelHeads in your network.
To verify that SMB signing has been disabled
1. Copy some files in Windows from the server to the client through the SteelHeads.
2. Connect to the Management Console. For detailed information, see the SteelHead Management Console User’s Guide.
3. On the server-side SteelHead, choose Reports > Diagnostics: System Logs.
4. Look for the SMB signing warnings (in red). For example, look for the following text:
SFE: error=SMB_SHUTDOWN_ERR_SEC_SIG_ENABLED
To disable SMB signing on Windows 2003 Domain Controllers, member servers, and clients
1. Open Active Directory Users and Computers on the Domain Controller.
2. Right-click Domain Controllers and select Properties.
3. Select the Group Policy tab.
4. Click Default Domain Controllers Policy.
5. Click Edit.
6. Click Default Domain Controllers Policy/Computer Configuration/Windows Settings/Security Settings/Local Policies/Security Options.
7. Reboot all the Domain Controllers and member servers that you want to optimize.
Unavailable Opportunistic Locks
If a file is not optimized for more than one user at a time, it might be because an application lock on it prevents other applications and the SteelHead from obtaining exclusive access to it. Without an exclusive lock, the SteelHead cannot perform latency (for example, read-ahead and write-behind) optimization on the file.
Without opportunistic locks (oplocks), RiOS SDR and compression are performed on file contents, but the SteelHead cannot perform latency optimization because data integrity cannot be ensured without exclusive access to file data.
The following behaviors are signs of unavailable oplocks:
• Within a WAN:
– A client, PC1, in a remote office across the WAN can open a file it previously opened in just a few seconds.
– Another client, PC2, on the WAN has also previously opened the file but cannot open it quickly because PC1 has it open. While PC1 has the file open, it takes PC2 significantly longer to open the file.
– When PC1 closes the file, PC2 can once again open it quickly. However, because PC2 has the file open, PC1 cannot open it quickly; it takes significantly longer for PC1 to open the file because PC2 has it open.
– If no client has the file open, and PC1, PC2, and a third client on the WAN (PC3) simultaneously copy but do not open the file, each client can copy the file quickly and in nearly the same length of time.
• The results of a tcpdump show that WAN utilization is low for files that take a long time to open.
• In the Management Console, slow connections appear optimized.
Tip: You can check connection bandwidth reduction in the Bandwidth Reduction report in the Management Console.
For similar problems, see:
Solution: None Needed
To prevent any compromise to data integrity, the SteelHead only accelerates access to data when exclusive access is available. When unavailable oplocks prevent the SteelHead from performing latency optimization, the SteelHead still performs RiOS SDR and compression on the data. Therefore, even without the benefits of latency optimization, SteelHeads might still increase WAN performance, but not as effectively as when application optimized connections are available.
Underutilized Fat Pipes
A fat pipe is a network that can carry large amounts of data without significantly degrading transmission speed. If you have a fat pipe that is not being fully utilized and you are experiencing WAN congestion, latency, and packet loss as a result of the limitations of regular TCP, consider the solutions outlined in this section.
Solution: Enable High-Speed TCP
To better utilize fat pipes such as in GigE WANs, consider enabling high-speed TCP (HS-TCP). HS-TCP is a feature that you can enable on SteelHeads to ease WAN congestion caused by limitations with regular TCP that results in packet loss. Enabling the HS-TCP feature enables more complete utilization of long fat pipes (high‑bandwidth, high-delay networks).
Important: Riverbed recommends that you enable HS-TCP only after you have carefully evaluated whether it will benefit your network environment. For detailed information about the trade-offs of enabling HS-TCP, see the tcp highspeed enable command in the Riverbed Command-Line Interface Reference Manual.
To display HS-TCP settings, use the show tcp highspeed command. To configure HS-TCP, use the tcp highspeed enable command. Alternatively, you can configure HS-TCP in the Management Console.
For details, see the Riverbed Command-Line Interface Reference Manual or the SteelHead Management Console User’s Guide.
MTU Sizing
This section describes how SteelHeads work with PMTU Discovery and references RFC 1191 to negotiate Maximum Transmission Unit (MTU) sizing. This section includes the following topics:
The MTU specifies the largest datagram packet (Layer-3 packet) that a device supports. In SteelHead optimized environments, MTU sizing is typically automatic and not a concern. The default MTU size for a SteelHead is 1500 bytes, which is the standard for many client and networking devices, especially across WAN circuits.
For pass-through traffic for an in-path SteelHead without RSP, the SteelHead passes packets up to the supported packet size of the configured in-path MTU. The in-path MTU supports jumbo frame configuration. For 1-Gbps interface cards, the supported MTU is 9216 or 16110, and all 10-Gbps cards support 16110. For a full list of interface cards and their MTU support, go to
https://supportkb.riverbed.com/support/index?page=content&id=s14344.
For optimized traffic, the SteelHeads act as a proxy. A separate inner TCP connection is established between SteelHeads, with a potentially different MTU size from the original client-to-server connection.
When a SteelHead detects that a session can be optimized, it initiates a TCP session to the remote SteelHead using the IP flag don't fragment with packet size up to the value configured in the interface MTU (default 1500 bytes). In line with RFC 1191, if a router or device along the TCP path of the session (possibly originating a GRE tunnel) does not support the packet size, and because it is not allowed to fragment the packet, it can request the originator (the SteelHead) to reduce the packet size. It does this with an ICMP type 3, code 4 (34) packet that carries the desired maximum size and the sequence number of the packet exceeding the router's interface MTU.
A common reason devices support less than 1500 bytes the presence GRE tunnels used to establish VPNs. The 24-byte overhead GRE incurs effectively gives the tunnel interface an MTU of 1476 bytes.
Similar to the Path MTU Discover (PMTUD) behavior for most clients and servers, the SteelHead reduces the packet size for a given session after it receives the ICMP message from the device with the lower MTU. According to RFC 1191, Section 6.3, the SteelHead tries to send larger packets every 10 minutes. For details, go to
http://www.faqs.org/rfcs/rfc1191.html.In environments that support PMTUD, Riverbed recommends that you leave the SteelHead MTU configuration to its default setting of 1500 bytes.
Note: In environments that support PMTUD, use the ip rt-cache rebuilt-count 0 command on communicating SteelHeads (RiOS v8.0 and later).
MTU Issues
In most cases two hosts dynamically negotiate path MTU. Networks that contain firewalls or tunnels (VPN, GRE, IPSec transport mode) between SteelHeads sometimes require manual tuning of the MTU values. Firewalls and tunnels interfere in the following ways:
• Firewalls can contain rules that explicitly prevent path MTU by blocking or not sending the ICMP type 3 packets, causing all attempts at dynamically negotiating MTU to fail.
• Tunnels require additional per-packet overhead to encapsulate data, reducing possible MTU size for connections being carried.
SteelHeads set the DF bit for inner channel communication to peer SteelHeads. If the device in the network path does not support the SteelHead packet size and also does not send an ICMP type 3 to notify the SteelHead to reduce packet size, the packet is dropped without the SteelHead knowing to reduce future packet sizes. This can result in poor optimization performance.
Determining MTU Size in Deployments
A simple method of determining MTU size across a path is to send do not fragment ping requests from the client PC, or client-side SteelHead, with varying packet sizes to a remote server or SteelHead. The following procedure shows the method from a windows client.
In the following example, a ping with the don't fragment (-f) and length (-l) 1500 bytes is sent to the remote server or SteelHead. This results in 100% loss with Packet needs to be fragmented but DF set in the reply. Pinging 10.0.0.1 with 1500 bytes of data:
C:\>ping -f -l 1500 10.0.0.1
Packet needs to be fragmented but DF set.
Packet needs to be fragmented but DF set.
Packet needs to be fragmented but DF set.
Packet needs to be fragmented but DF set.
Ping statistics for 10.0.0.1:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss)
Decrease the size of the packet to 1400 and repeat, pinging 10.0.0.1 with 1400 bytes of data:
C:\> ping -f -l 1400 10.0.0.1
Reply from 10.0.0.1: bytes=1400 time=222 ms TTL=251
Reply from 10.0.0.1: bytes=1400 time=205 ms TTL=251
Reply from 10.0.0.1: bytes=1400 time=204 ms TTL=251
Reply from 10.0.0.1: bytes=1400 time=218 ms TTL=251
Ping statistics for 10.0.0.1:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss)
Approximate round trip times in milliseconds:
Minimum = 204 ms, Maximum = 222 ms, Average = 212 ms
This command gets the desired result. Repeat the ping test increasing or decreasing in increments of 10 or 20 until reaching the optimum value.
Note: Packet size of 1400 is shown only as an example, typical values can range from 1280 and higher.
When you specify the -l <size> command on a Windows machine, you are actually specifying the data payload, not the full IP datagram, including the IP and ICMP headers. To calculate the appropriate MTU, you must add the IP header (20 bytes) and ICMP header (8 bytes) to the Windows ping size. For example, for sending a 1400 byte payload, the SteelHead in-path MTU should be set to 1428 bytes. Although specifying ping sizes on Cisco routers, the specified size includes the IP and ICMP header (28 bytes). If using a Cisco device to test, set the MTU to the specified size; adding the 28 bytes manually is not necessary.
How to configure the in-path MTU value
1. Choose Networking > Networking: In-Path Interfaces, and expand the interface you want to edit.
2. Change the MTU value and apply the setting.
In RiOS v8.0 and later, the SteelHead does not pass through packets larger than the MTU value of its interfaces, nor does it send ICMP notifications to the sending host of the dropped packets. In environments in which the in-path MTU is lowered to account for a smaller MTU in the WAN network, Riverbed recommends that you use the interface mtu-override enable command.
Connection-Forwarding MTU Considerations
In networks in which SteelHeads are connection-forwarding neighbors, it is critical that you configure the LAN or WAN links that are expected to carry forwarded traffic so they can support the configured in-path MTU. Connection-forwarded traffic does not support PMTUD.
When forwarded packets are too large, ICMP Type 3, Code 4 messages are generated on intermediate routers are sent back to the sending client or server. The ICMP header does not match a TCP connection in the client or server, which causes poor optimization or failed connections. To prevent poor optimization or failed connections, make sure that you configure the interface MTUs on links carrying forwarded traffic the same size as the SteelHead in-path interface.