Data Protection Deployments
This chapter describes the configuration and deployment of SteelHeads for data protection solutions. By leveraging SteelHeads, you can achieve higher levels of data protection, streamlined IT operations, and reduced WAN bandwidth.
This chapter includes the following sections:
Overview of Data Protection
To secure and recover important files and data, more data center-to-data center environments (or branch office-to-data center environments) are using WAN-based backup and data replication (DR). WAN optimization is now a critical part of data protection environments because it can substantially reduce the time it takes to replicate data, perform backups, and recover data. Backup and replication over the WAN ensures that you can protect data safely at a distance from the primary site, but it can also introduce new performance challenges. To meet these performance challenges, Riverbed provides hardware and software capabilities that help data protection environments in the following ways:
• Reduce WAN Bandwidth - By reducing WAN bandwidth, SteelHeads can lower the total cost of current data protection procedures and, in some cases, make WAN-based backup or replication possible where it was not before.
• Accelerate Data Transfer - By accelerating data transfer, SteelHeads meet or improve time targets for protecting data.
Figure: Data Protection Deployment Using WAN-Based Replication
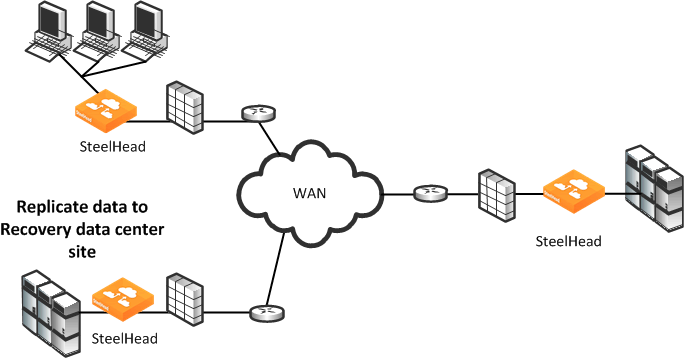
Planning for a Data Protection Deployment
This section describes methods for planning a successful data protection deployment. You must consider several variables, each of which can have a significant impact on the model, number, and configuration of SteelHeads required to deliver the required result. This section includes the following topics:
Riverbed strongly recommends that you read both of these sections and complete the questionnaire. Riverbed also recommends that you consult with Riverbed Professional Services or an authorized Riverbed Delivery Partner when planning for a data protection deployment.
For information about the other factors to consider before you design and deploy the SteelHead in a network environment, see
Choosing the Right SteelHead Model.
LAN-Side Throughput and Data Reduction Requirements
This section describes requirements and configurations from LAN-side throughput and data reductions. This section includes the following topics:
The basis for correctly qualifying, sizing, and configuring SteelHeads for use in a data protection environment depends on that the deployed SteelHeads can:
• receive and process data on the LAN at the required rate (LAN-side throughput), and
• reduce the data by a certain X-Factor, to
• transfer data given certain WAN-side bandwidth constraints.
These constraints are defined by the following formula:
LAN-side Throughput / X-Factor <= WAN-side Bandwidth
You derive the LAN-side throughput requirements from an understanding of the maximum amount of data that must be transferred during a given time period. Often, the time allotted to transfer data is defined as a target Recovery Point Objective (RPO) for your organization.
The RPO describes the acceptable amount of data loss measured in time. You must recover data at this time. RPO is generally a definition of what an organization determines is an acceptable data loss following a disaster; it is measured in seconds, minutes, hours, days, or weeks. For example, an RPO of 2 hours means that you can always recover the state of data 2 hours in the past.
The X-Factor describes the level of data reduction necessary to fit the LAN data into the WAN link. For example, if LAN-side throughput required to meet RPO is 310 Mbps and WAN-side bandwidth available is 155 Mbps, then X-Factor is 2x. X-Factor is highly dependent on the nature of the data, but in practice it generally ranges from 2x (for LZ-only compression) to 4-8x (for default SDR mode).
Configuring a Nightly Full Database Backup
Objective:
“I want to copy 1.8 TB of nightly database dumps over my OC-3 within a 10-hour window.”
Formula:
1.8 TB / 10 hours = 400 Mbps
Solution:
An OC-3 link has a capacity of 155 Mbps. To deliver 400 Mbps, the SteelHead must reduce the total bandwidth over the WAN by 400/155 = 2.58x.
Configuring a Daily File Server Replication
Objective:
“After consolidating the NetApp file servers from branch offices, I expect daily SnapMirror updates from my data center to go from 400 GB to 4 TB per day. I have a designated DS-3 that is nearly maxed out. Can the SteelHead help me replicate all 4 TB each day using my DS-3?”
Formula:
4 TB / 1 day = 370 Mbps
Solution:
A DS-3 link has a capacity of 45 Mbps. To deliver 370 Mbps, the SteelHead must reduce the total bandwidth over the WAN by 370/45 = 8.2x. This bandwidth is within the range of data reduction that the SteelHead can achieve using default SDR, depending on the amount of redundancy present in the data streams.
Configuring a Very Large Nightly Incremental Backup
Objective:
“The incremental Tivoli Storage Manager (TSM) backup at a remote site is typically 600 GB and the backup window each night is 8 hours. Can I perform these backups over the WAN using a T1 link?”
Formula:
600 GB / 8 hours = 166 Mbps
Solution:
A T1 link has a capacity of 1.5 Mbps. To deliver 166 Mbps, the SteelHeads must reduce the total bandwidth over the WAN by 166/1.5 = 110x. This bandwidth is a very high level of reduction that is typically out of range for data protection deployments.
To support backups over the WAN, you must upgrade the WAN link. A T3 link, for example, has a capacity of 45 Mbps. Using a T3 link, the SteelHeads needs to achieve a data reduction of 166/45 = 3.7x, which is attainable for many deployments.
Predeployment Questionnaire
To organize and take a survey of the WAN-side, LAN-side, and X-Factor considerations, use the predeployment questionnaire in the following table. Discuss your completed survey with Riverbed Professional Services or an authorized delivery partner to determine the best model, number, and initial configuration of the SteelHeads to deploy.
For a Microsoft Word version of the Data Protection questionnaire go to
http://splash.riverbed.com/message/3194.Question | Why This Is Important |
WAN-Side Considerations |
Is this a two-site or a multisite (fan-in, fan-out) data protection opportunity? | In a two-site deployment, the same SteelHead models are often selected for each site. In a multisite (fan-in, fan-out) deployment, the SteelHead at the central site is sized to handle the data transfers to and from the edge sites. |
What is the WAN link size? | Knowing the WAN link size is essential in determining: • which models are feasible for deployment because the SteelHeads specifications are partially based on the WAN rating. • the level of data reduction the SteelHeads must deliver to meet the ultimate data protection objective. |
What is the network latency between sites? | Knowing the latency in the environment is essential for providing accurate performance estimates. Network latency and WAN link size are used together to calculate buffer sizes on the SteelHead to provide optimal link utilization. Although SteelHeads are generally able to overcome the effects of latency for network protocols used in data protection solutions, some are still latency sensitive. |
Is there a dedicated link for disaster recovery? | Environments with a dedicated link are typically easier to configure. Environments with shared links must employ features such as QoS to ensure that data protection traffic receives an adequate amount of bandwidth necessary to meet the ultimate objective. |
LAN-Side Considerations |
Which backup or replication products are you using? | Certain backup or replications products require special configuration. Knowing what is currently in use is essential for providing configuration recommendations and performance estimates. Riverbed has experience with different data protection products and business relationships with many different replication vendors. Many have similar configuration options and network utilization behaviors. Some examples of backup and replication products: • EMC - SRDF/A RecoverPoint • NetApp - SnapMirror, SnapVault • IBM - GlobalMirror, XIV replication • HDS - TrueCopy, Hitachi Universal Replicator • Symantec - NetBackup • Vision Solutions - Double-Take • CA - ARCserver • HP - Continuous Access EVA • HDS - TrueCopy • IBM - PPRC |
Are you using synchronous or asynchronous replication? | Asynchronous replication is typically a very good fit. By comparison, synchronous replication has very stringent latency requirements and is rarely a good fit for WAN optimization. Many types of data protection traffic are not typically considered replication of either type, such as backup jobs. |
What is your backup methodology? | Knowing the backup type and schedule provides insight into the frequency of heavy data transfers and the level of repetition within these transfers. Some examples of backup methodologies are: • A single full backup and an incremental backup for life (synthetic full). • A daily full backup. • A weekly full backup and a daily incremental backup. |
Are your data streams single or multistream? What is the total number of replication streams? | Knowing the number of TCP streams is essential in providing a configuration recommendation and performance estimate. Because SteelHeads proxy TCP/IP, the number of TCP streams created by the data protection solution can impact the SteelHead resource utilization. • RiOS 5.0 and earlier have a constraint that each TCP session (stream) is serviced by a single CPU core, so splitting the load across many streams is essential to fully use the resources in larger, multicore SteelHeads. • RiOS 5.5 or later has multicore features that allow multiple CPU cores to process a single stream. When considering the number of streams, of primary importance is the number of heavyweight data streams that carry significant amounts of traffic. In addition, consider that any smaller control streams that carry a small amount of traffic (such as these streams present in many backup systems and some FCIP systems). Depending on the data protection technology in use, there might be options to increase the number of streams in use. As a first step, determine how many streams are observed in the current environment. Determine whether there is a willingness to increase the number of data streams if a method to do so is suggested. |
Is there a FCIP/iFCP gateway? If yes, what is the make, model, and firmware version? | Some FCIP/iFCP gateways (or particular firmware versions of some gateways) do not adhere fully to the TCP/IP or FCIP standards. Depending on what is in use they might require firmware upgrades, special configuration, or cannot be optimized at this time. Gateways are mainly seen in fibre channel SAN replication environments such as SRDF/A, MirrorView, and TrueCopy. Typical firmware versions: Cisco MDS, FCIP v4.1(3) Brocade 7500 FOS v6.3.1, QLogic isr6142 v2.4.3.2. |
Is compression enabled on the gateway or the replication product? If yes, what is the current compression ratio? | Most data protection environments using FCIP or iFCP gateways use their built-in compression method, because this is a best practice of the product vendors and the SAN vendors who configure them. However, the best practice for WAN optimization of these technologies is to disable any compression currently in use and employ the SteelHead optimization instead. The first-pass LZ compression in the SteelHead typically matches the compression already in use and then RiOS SDR allows for an overall level of data reduction that improves the previous compression ratio. Knowing the current compression ratio achieved using the built-in compression method is important in determining whether the SteelHeads can improve upon it. |
Are SteelHeads already deployed? If yes, what is their make and the RiOS version? | If the environment already has SteelHeads deployed and data protection is a new requirement, knowing the current appliance models in use can determine if adequate system resources are available to meet the objectives without adding additional hardware. Knowing the current RiOS version is essential in determining what features and tuning opportunities are available in the RiOS release to provide the optimal configuration for data protection. If the environment does not already use SteelHeads, Riverbed can recommend the ideal RiOS version based on the environment and data protection objective. |
X-Factor Considerations |
How much new incremental data is added daily or hourly? | The rate of change information is extremely useful alongside the dataset size information to provide accurate performance estimates. If a dataset is too large for a single RiOS data store to find the data patterns for the entire dataset without wrapping continuously, Riverbed can plan system resources based on servicing the amount of data that changes hourly or daily. |
What is the total size of the dataset? | For some data protection solutions such as backup, knowing the dataset size is extremely important for RiOS data store sizing. Ideally you want to select SteelHeads that can find the data patterns for the entire dataset without continuously wrapping the RiOS data store. For SAN-based solutions this information can be more difficult to gather, but even rough estimates can help. For example, you can estimate the size of the Logical Unit Number (LUNs) that are subject to replication or the size of the databases stored on an array. |
What is the dataset type? For example, Exchange, VMware, SQL, or file system. | Different types of data exhibit different characteristics when they appear on the network as backup or replication traffic. For example, file system data or VMware images often appear as large, sequential bulk transfers and lend themselves well to disk-based data reduction. On the other hand, real-time replication of SQL database updates can often present a workload that requires heavy amounts of disk seeks. These types of workloads can lend themselves better to a memory-based approach to data reduction. |
Is the data pre-compressed? | You must determine if precompressed data is present for accurate performance estimates. Data stored at the point of origin in a precompressed format (such as JPEG images, video, or any type of data that has been compressed separately with utility tools such as WinZip), might see limited data reduction from SteelHeads. |
Is the data encrypted? | Data stored at the point of origin in a preencrypted format (such as DPM-protected documents or encrypted database fields and records) might see limited data reduction from the SteelHead. |
How repeatable is the data? | You must determine if repeatable data is present for accurate performance estimates. Data that contains internal repetition (such as frequent, small updates to large document templates) typically provide very high levels of data reduction. |
What LAN-side throughput is needed to meet the data protection goal? | It is the speed of data going in and out of the systems on the LAN that establishes whether the data protection objectives can be met. The LAN-side throughput can be calculated by dividing the total amount of changed data by the time window for the replication or backup job. The WAN-side throughput and level of data reduction represent the level of optimization. |
Configuring SteelHeads for Data Protection
After you deploy the SteelHeads and perform the initial configuration, you can use the features described in this section to deliver an optimal data protection deployment. This section includes the following data protection features:
You can configure the SteelHead features relevant to data protection in the Management Console in the Optimization > Data Replication: Performance page.
Figure: Performance Page Data Streamlining Features
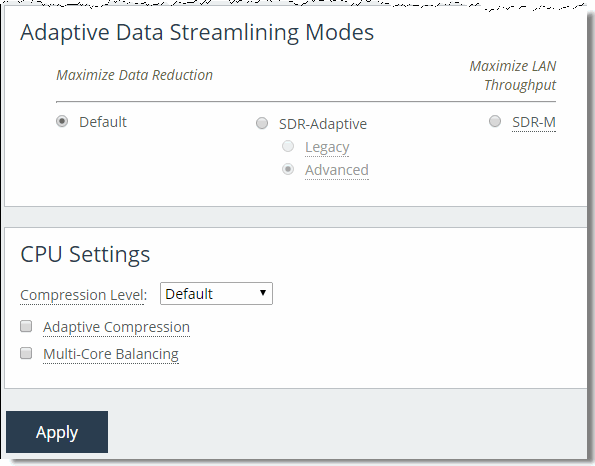
Adaptive Data Streamlining Feature Settings
Adaptive data streamlining provides you with the ability to fine tune the data streamlining capabilities and enables you to obtain the right balance between optimal bandwidth reduction and optimal throughput.
The following table describes the adaptive data streamlining settings.
Adaptive Data Streamlining Setting | Benefit | Description |
Default SDR/Classic Data Streamlining | Best data reduction | By default, SteelHeads use their disk-based RiOS data store to find data patterns that traverse the network. Previously seen data patterns do not traverse the network in their fully expanded form. Instead, a SteelHead sends a unique identifier for the data to its peer SteelHead, which sends the fully expanded data. In this manner, data is streamlined over the WAN because unique content only traverses the link once. |
SDR-Adaptive | Good data reduction and LAN-side throughput | Dynamically blends different data streaming modes to enable sustained throughput during periods of high disk/CPU-intensive workloads. Legacy - Monitors disk I/O response times and CPU load, and based on statistical trends employs a blend of disk-based deduplication and compression-based data reduction techniques. Use caution with the Legacy setting, particularly when optimizing CIFS or NFS with prepopulation. For more information, contact Riverbed Support. Advanced - Monitors disk I/O response times, CPU load, and WAN utilization, and based on statistical trends employs a blend of disk-based deduplication, memory-based deduplication and compress-based data reduction techniques. |
SDR-M | Excellent LAN-side throughput | Performs data reduction entirely in memory, which prevents the SteelHead from reading and writing to and from the disk. Enabling this option can yield high LAN-side throughput because it eliminates all disk latency. SDR-M is typically the preferred configuration mode for SAN replication environments. SDR-M is most efficient between two identical high-end SteelHead models. When SDR-M is configured between two different SteelHead models, the smaller model limits the performance. When you use RiOS SDR-M, RiOS data store synchronization is not possible because none of the data is written to the disk-based data store. For information about data store synchronization, see RiOS Data Store Synchronization. |
CPU Settings
CPU settings provide you with the ability to balance throughput with the amount of data reduction and balance the connection load. The CPU settings are useful with high-traffic loads to scale back compression, increase throughput, and maximize Long Fat Network (LFN) utilization. This section includes the following topics:
Compression Level
The compression level specifies the relative trade-off of LZ data compression for LAN throughput speed. Compression levels 1 to 9 can be specified for fine-tuning. Generally, a lower number provides faster throughput and slightly less data reduction. Setting the optimal compression level provides greater throughput, although maintaining acceptable data reduction.
Riverbed recommends setting the compression to level 1 in high-throughput environments such as data-center-to-data-center replication.
Note: The setting is ignored on SteelHead models that are equipped with hardware compression cards.
Adaptive Compression
The adaptive compression feature detects the LZ data compression performance for a connection dynamically and turns it off (that is, sets the compression level to 0) momentarily if it is not achieving optimal results. Enabling this feature can improve end-to-end throughput in cases where the data streams are not further compressible.
Multicore Balancing
Multicore balancing distributes the load across all CPUs, which maximizes throughput. Multicore balancing improves performance in cases where there are fewer connections than the total number of CPU cores on the SteelHead. Without multicore balancing, the processing of a given connection is bound to a single core for the life of the connection. With multicore balancing, even a single connection leverages all CPU cores in the system.
Best Practices for Data Streamlining and Compression
Riverbed recommends the following best practices for data protection scenarios:
• For SAN replication environments (especially with high bandwidth), start with a SDR-M setting and deploy the same model SteelHead on each side.
• When replicating database log files, the LZ-only compression level typically provides optimal results because database log files contain few repetitive data sequences that can be deduplicated using RiOS SDR.
• For replication of email repositories such as Microsoft Exchange and Lotus Notes, select an appropriate mode of SDR. If WAN capacity is a bottleneck to end-to-end throughput, select a mode that delivers the highest levels of data reduction, such as default SDR or SDR-A. If WAN capacity is not the bottleneck, select a less aggressive form of data reduction, such as SDR-M or Turbo SDR.
• Always set the compression level to 1 in high-throughput data center-to-data center replication scenarios.
For more information about best practice guidelines and configuration settings, see
Common Data Protection Deployments.
MX-TCP Settings
Maximum TCP (MX-TCP) enables data flows to reliably reach a designated level of throughput, which is useful in data protection scenarios where either:
• a dedicated link is used for data protection traffic.
• a known percentage of a given link can be fully consumed by data protection traffic.
For example, if an EMC SRDF/A replication deployment is using peer SteelHeads that are connected to a dedicated OC-1 link (50 Mbps), then you can create an MX-TCP class of 50 Mbps on each SteelHead. In this example, SRDF/A uses port 1748 for data transfers.
On both the client-side and server-side SteelHeads, enter the following commands:
qos shaping interface wan0_0 rate 50000
qos shaping interface wan0_0 enable
qos classification enable
qos classification class add class-name "blast" priority realtime min-pct 99.0000000 link-share 100.0000000 upper-limit-pct 100.0000000 queue-type mxtcp queue-length 100 parent "root"
qos classification rule add class-name "blast" traffic-type optimized destination port 1748 rulenum 1
qos classification rule add class-name "blast" traffic-type optimized source port 1748 rulenum 1 write memory
restart
If you cannot allocate a given amount of bandwidth for data protection traffic, but you still require high bandwidth, enable High-Speed TCP (HS-TCP) on peer SteelHeads.
Note: To configure MX-TCP, you must enable advanced outbound QoS on the SteelHead. For more information, see
MX-TCP.
For information about fat pipes, see
Underutilized Fat Pipes. For information about MX-TCP, see
MX-TCP.
For more information about MX-TCP as a transport streaming lining mode, see
Overview of Transport Streamlining.
SteelHead WAN Buffer Settings
In all data protection scenarios, set the SteelHead WAN buffers to at least 2 x BDP. For example, if NetApp SnapMirror traffic is using a dedicated OC-1 link (50 Mbps) with 30 ms of latency (60 ms round-trip time) between sites, then set the SteelHead WAN-side buffers to:
On all SteelHeads in this environment that send or receive the data protection traffic, enter the following commands:
protocol connection wan send def-buf-size 750000
protocol connection wan receive def-buf-size 750000
write memory
restart
Router WAN Buffer Settings
In environments where a small number of connections are transmitting high-throughput data flows, you must increase the WAN-side queues on the router to the BDP.
For example, consider an OC-1 link (50 Mbps) with 60 ms latency (RTT):
BDP = 50 Mbps * 1,000,000 b/Mb * 60 ms * (1/1000) s/ms * (1/8) Bytes/bit * (1/1500) Bytes/packet
= 250 Packets
On the Cisco router, enter the following hold-queue interface configuration command:
hold-queue 250 out
You do not need to increase the router setting when using MX-TCP because MX-TCP moves bottleneck queueing onto the SteelHead. This feature allows WAN traffic to enter the network at a constant rate, eliminating the need for excess buffering on router interfaces.
Common Data Protection Deployments
This section describes common data protection deployments. This section includes the following topics:
Remote Office, Branch Office Backups
The remote office, branch office (ROBO) data protection deployment is characterized by one or more small branch office locations, each of which backs up file data from one or more file servers, PCs, and laptops to a central data center. Common applications include Veritas NetBackup, EMC Legato, CommVault Simpana, Sun StorageTek, and backups performed over standard protocols like CIFS and FTP.
In these deployments, WAN links are relatively small, commonly ranging from 512 Kbps on the low end to 10 Mbps on the high end. Also distinct from data center-to-data center replication scenarios where dedicated SteelHeads are typically used exclusively for replication, ROBO backup procedures commonly use the same branch office SteelHeads that are used to accelerate other applications, like CIFS and MAPI. For both of these reasons, ROBO backups commonly require relatively larger levels of WAN bandwidth reduction.
In the Performance page (
Figure: Performance Page Data Streamlining Features), enter the initial configuration of the peer SteelHeads as follows:
• Set the Adaptive Streamlining mode to Default - Due to limited WAN bandwidth in these deployments, it is important to maximize WAN data reduction. The default setting uses disk-based SDR to provide maximum data reduction. File backup workloads typically result in sequential disk access, which works well for disk-based SDR.
• Set the Compression Level to 6 - Start with aggressive compression to minimize WAN bandwidth.
• Enable Multicore balancing - This option allows the SteelHead to use all CPU cores even when there are a small number of connections. Small connection counts can occur if backups are performed nightly, when minimal or no additional traffic is generated.
Network Attached Storage Replication
Network attached storage (NAS) data protection deployment sends primary file data over the WAN to online replicas. Common applications include NetApp SnapMirror, EMC VNX Replicator, and VNX Celerra Replicator.
For information about EMC qualification matrix for Riverbed Technology, see the Riverbed Knowledge Base article
Deploying SteelHeads with EMC Storage, at
https://supportkb.riverbed.com/support/index?page=content&id=s13363.
In NAS replication deployments, WAN links are typically large, ranging from T3 (45 Mbps) to OC-48 (2.5 GB). Often NAS replication solutions require dedicated links used exclusively by the NAS replication solution.
As a best practice for high-speed NAS replication solutions, use SteelHeads that are dedicated to only optimizing high-speed NAS replication workloads and that do not optimize large amounts of general application or end-user traffic. Doing this benefits you for the following reasons:
• Increase both the level and predictability of performance delivered by SteelHeads, leading to consistent delivery of recovery point and time objectives (RPO/RTO).
• With separate SteelHeads, the large data sets commonly associated with high-speed replication do not compete for SteelHead data store resources with other user-based traffic, and the reverse.
• You can optimally tune separate SteelHeads for their respective workloads.
Disable any data compression applied on the storage device so that data enters the SteelHead in its raw form. Disabling data compression enables the SteelHead to perform additional bandwidth reduction using SDR.
In the Performance page (
Figure: Performance Page Data Streamlining Features), enter the initial configuration of the peer SteelHeads as follows:
• Set the Compression Level to 1 - Higher compression levels produce additional gains in WAN-side bandwidth reduction, but often at a large cost to the CPU resources, which ultimately throttles LAN-side throughput.
• Enable Multicore Balancing - Often there are a small number of connections made between storage devices. This option enables the optimization services to balance their processing across all CPU cores.
• Enable MX-TCP or HS-TCP - If there is a dedicated WAN-link for the NAS replication traffic or if you know how much bandwidth on a shared link can be allocated to the data transfer, create an MX-TCP class covering the data traffic. If not, enable HS-TCP. If HS-TCP is enabled, increase the router queue length to the BDP. Configure MX-TCP on the QoS Classification page.
• Set the SteelHead WAN buffers to 2 x BDP - This option allows the SteelHeads to buffer enough data to continue accepting data from the LAN—even in cases of WAN packet loss.
In cases where WAN links exhibit high-packet loss, you might need to increase the SteelHead WAN buffers higher than 2 x the BDP for optimal throughput.
Storage Area Network Replication
Storage area network (SAN) data protection deployment includes SAN replication products such as EMC Symmetrix Remote Data Facility/Asynchronous (SRDF/A), IBM Global MirrorIBM Global Mirror, and Hitachi Universal Replicator, including full and incremental backups of databases like Oracle and Exchange.
For more information about SAN replications, see
Storage Area Network Replication.
Designing for Scalability and High Availability
Scalability and high availability are often required in data protection deployments. This section describes the design of data protection solutions which address both requirements. This section includes the following topics:
For more information about high availability, see
Multiple WAN Router Deployments.
Overview of N+M Architecture
The most cost-effective way to provide scalability and high availability is by using an N+M SteelHead architecture or an N+M deployment. In an N+M architecture, N represents the minimum number of SteelHeads that are required to process the total amount of traffic from site to site. M represents the number of additional SteelHeads needed to provide a desired amount of redundancy. For example, a common requirement is to maintain availability in the presence of a single failure. In this case, you can use a N+1 SteelHead deployment architecture.
Using MX-TCP in N+M Deployments
This section describes how to use MX-TCP in N+M deployments. This section includes the following topics:
MX-TCP is typically used in data protection deployments when all or part of the WAN bandwidth is dedicated to the data transfers. When using MX-TCP with multiple SteelHeads, MX-TCP settings are set on each SteelHead so that the collection of SteelHeads uses the available WAN bandwidth.
In an N+M deployment, the following options effect how to configure MX-TCP:
• All Active, or N+M Active - All N+M SteelHeads participate in optimizing the data transfer. Configure MX-TCP on each SteelHead to use 1/(N+M)th of the total available WAN bandwidth. For example, in a 2+1 All Active deployment, configure MX-TCP on each SteelHead to use one-third of the available bandwidth. Less WAN bandwidth is used when one or more SteelHeads are offline. For example, in a 2+1 All Active deployment with one SteelHead offline, two-third of the allocated WAN bandwidth is used by the SteelHeads that remain online.
• Active and Backup, or N Primary + M Backup - Exactly N SteelHeads participate in optimizing the data transfer. Configure MX-TCP on each SteelHead to use 1/Nth of the total available WAN bandwidth. If one or more active SteelHeads are offline, backup SteelHeads are used to keep the WAN fully utilized. For example, in a 2+1 Active and Backup deployment, configure MX-TCP on each SteelHead to use one-half of the available bandwidth. If one active SteelHead is offline, the backup SteelHead participates in optimizing the data transfer, keeping the WAN fully utilized.
Interceptor and N+M Active and Backup Deployment
When configuring the SteelHead Interceptor for an N+M Active and Backup deployment using the SteelHead Interceptor, load-balance rules are defined which carry out the following actions:
• Balance load across the primary SteelHeads
• Use backup SteelHead in the event of a failure
Figure: Interceptor N+M shows a 2+1 Active and Backup deployment.
Figure: Interceptor N+M
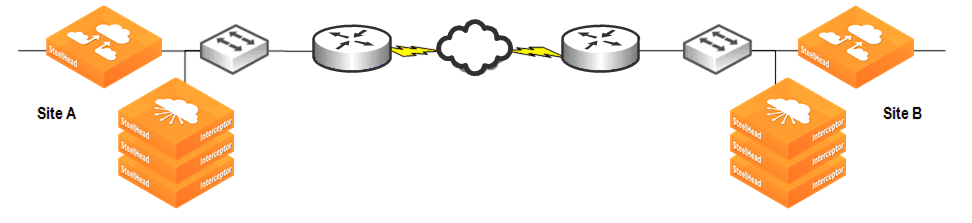
In each site there is a SteelHead Interceptor and three SteelHeads: two are primary and one is the backup. Connections are established from Site A to Site B, and there are four hosts (not depicted) at each site that process equal amounts of data. The following list shows IP addresses for the hosts and SteelHeads at Site A:
• Hosts 1-4: 10.30.50.11 - 10.30.50.14
• Primary SteelHead 1: 10.30.50.15
• Primary SteelHead 2: 10.30.50.16
• Backup SteelHead: 10.30.50.17
The following load-balance rules are used on each SteelHead Interceptor to evenly split the connections established from the four hosts at Site A across the two primary SteelHeads (odd-numbered hosts are redirected to primary SteelHead 1, and even-numbered hosts are redirected to primary SteelHead 2).
load balance rule redirect addrs 10.30.50.15 src 10.30.50.11/32
load balance rule redirect addrs 10.30.50.16 src 10.30.50.12/32
load balance rule redirect addrs 10.30.50.15 src 10.30.50.13/32
load balance rule redirect addrs 10.30.50.16 src 10.30.50.14/32
The following load-balance rules allow the SteelHead Interceptor to use the backup SteelHead in case either of the primary SteelHeads fails:
load balance rule redirect addrs 10.30.50.17 src 10.30.50.11/32
load balance rule redirect addrs 10.30.50.17 src 10.30.50.12/32
load balance rule redirect addrs 10.30.50.17 src 10.30.50.13/32
load balance rule redirect addrs 10.30.50.17 src 10.30.50.14/32
The same configuration would be used for the SteelHead Interceptor at Site B, using instead of the IP addresses for the SteelHeads in site B.
Interceptor and Pass-Through Connection Blocking Rules
In some data protection deployments, it is important to prevent backup and replication connections from being established as unoptimized, or pass-through, connections. These unoptimized connections can have a negative impact on meeting LAN and WAN throughput objectives. Interceptor 2.0.3 or later supports Pass-through Connection Blocking Rules. This feature adds a set of rules that can break existing pass-through connections and prevent formation of new ones.
For example, you can create a pass-through blocking rule for port 1748, connect to the Interceptor CLI and enter the following command:
in-path passthrough rule block port start 1748 end 1748
For details, see the SteelHead Interceptor User’s Guide and the Riverbed Command-Line Interface Reference Manual.
Enhanced Visibility and Control for SnapMirror
The two varieties of SnapMirror are volume based and qtree based. SnapMirror replicates data from one volume or qtree (the source) to another volume or qtree (the mirror). SnapMirror periodically updates the mirror to reflect incremental changes to the source. The result of this process is an online, read-only volume (the mirror), that contains the same data as the source volume at the time of the most recent update.
You can use the information on the mirror to:
• provide quick access to data in the event of a disaster that makes the source volume or qtree unavailable. The secondary copy is nearly identical to the primary copy; every snapshot on the primary copy also exists on the backup copy. You can schedule updates as frequently as every minute.
• update the source to recover from disaster, data corruption (mirror qtrees only), or user error.
• archive the data to tape.
• balance resource loads.
• back up or distribute the data to remote sites.
With data streamlining, the SteelHead optimizes WAN performance for SnapMirror by removing repetitive data from the WAN. Transport streamlining enables TCP to be more efficient, minimizing round trips and maximizing end-to-end throughput. For environments using NetApp Data ONTAP v7 or Data ONTAP v8 operating in 7-mode, Riverbed provides additional capabilities to enhance the visibility and control of SnapMirror on a volume granular or qtree-granular basis. RiOS 8.5 or later allows you to:
• apply QoS traffic shaping policies on per-volume or qtree basis. You can assign mappings by filer and volume name to one of five volume priorities. Using advanced QoS, you can assign a service class and DSCP value to each volume priority when creating a rule for SnapMirror traffic. Multipath operations are not supported.
• customize SnapMirror traffic optimization on per-volume or qtree basis. You can apply desired optimization algorithms (SDR-Default, LZ-only, and None) for different data types that reside on targeted volumes or qtrees.
• collect and chart SnapMirror statistics such as the total LAN and WAN bytes in and out, throughput, the data reduction at the filer, and volume/qtree granularity.
To benefit from the improved SnapMirror optimization, both SteelHeads must be running RiOS 8.5 or later. SnapMirror optimization is disabled by default.
The following example shows a company with a NetApp filer that is replicating four volumes from New York to San Francisco. These four volumes contain the following data:
• Volume 1 - Contains archival data of the previous year. The data continues to reside on the primary storage because it is used regularly by the analytics department. However, to preserve server space, the data is stored in compressed format.
• Volume 2 - Contains graphics and videos. The data is encrypted or not compressible.
• Volume 3 - Contains an MS Exchange data store of the company users email mailboxes.
• Volume 4 - Contains lab data that for historical reasons is produced and stored in plain 7-bit ACSII format, but doesn't have repeatable patterns as usual text would.
Because the data composition varies by volume, to best use the SteelHead optimization resources, and to accomplish the best result on the data optimization, you can apply different optimization methods for each volume.
Data in Volume 1 and Volume 2 is neither compressible nor dedupable. If you enable SDR, you have a higher CPU optimization on the SteelHeads and you do not achieve the best use of the SDR data store. The SDR data store can provide higher data reduction to the rest of the data. However, the SteelHead can add value by sending the data using MX-TCP protocol. MX-TCP protocol enables the most of available bandwidth. Traditional TCP cannot accomplish this because of packet loss, high latency, or some combination of these and other impairments.
Data in Volume 3 benefits from SDR because it contains repeatable patterns in the data stream that can both be compressed and replaced with references.
Data in Volume 4 benefits from conventional compression or LZ-only type of SteelHead optimization.
Different volumes can have different change rates and, therefore, have replication service level agreements (SLAs) or recovery point and/or time objectives (RPO/RTO): for example, 4-hour RTO for MS Exchange and 24-hour RTO for images and video. To meet varied requirements, you can apply different QoS policies for those volumes to make increase priority of MS Exchange (Volume 3) data or image data (Volume 2).
For more information about the configuring SnapMirror on the SteelHead, see the SteelHead Management Console User’s Guide.
Troubleshooting and Fine-Tuning
If your data protection deployment is not meeting performance targets after configuring the SteelHeads using the methods described in this chapter, examine the following system components for potential bottlenecks:
• Application Servers - Are the server and client fast enough? To perform a LAN baseline check, put the SteelHeads in bypass mode and connect the servers directly through a high-bandwidth network with zero latency to see how fast they are. Time permitting, you might want to do this LAN baselining before introducing the SteelHeads into the test environment.
• LAN-Side Network - Make sure that there are no issues with the LAN-side network between the SteelHeads and any data protection hosts. In particular, on the LAN, there should be no packet loss, and the round trip latency between the SteelHeads and hosts should be less than one millisecond for the fastest possible throughput. Interface errors, especially those related to Ethernet duplex negotiation, are a leading factors of LAN-side network issues.
• WAN-Side Network - Use MX-TCP to overcome any WAN-side packet loss caused by deficient links or undersized router interface queues. If the WAN bandwidth is being fully utilized during optimized data transfers, then the WAN is the bottleneck. If the WAN link is not fully utilized, options like RiOS SDR-A or SDR-M can increase the LAN-side throughput.
• CPU - Check the CPU reports to see if the CPU cores are the bottleneck. If some cores are busy but some are not, enable multicore load balancing. If you enable multicore load balancing and all cores are fully utilized, you might require a larger model SteelHead.
• Disk - You can use disk-related metrics to determine that the disk is the bottleneck for higher levels of throughput. Always assess these metrics relative to empirical application performance. Even if they indicate heavy disk utilization, it does not necessarily mean that the disk is the bottleneck. In cases where the disk is the bottleneck, then you can adjust the adaptive data streamlining settings progressively upward to either SDR-A, SDR-M or, finally, compression-only. In some cases, you might need to upgrade to a higher model SteelHead. Consult with your Riverbed Sales or Professional Services representative.
• Data Store Disk Load - If the RiOS Data Store Read Efficiency report, accessible from the Management Console, shows that read efficiency falls below 50% consistently, this might indicate that the disk is the bottleneck.
Third-Party Interoperability
Riverbed optimizes data protection utilities from many storage vendors, including but not limited to the following:
• EMC
• NetApp
• HP
• Hitachi Data Systems (HDS)
• IBM
• Dell
• QLogic
• Symantec/Veritas
• Microsoft
• Commvault
• DoubleTake
• CA
• Compellent
• 3Par
• BlueArc
For additional information go to the following websites:
Alternatively, you can consult with your authorized Riverbed Solutions Provider.