Configuring SteelHeads for Data Protection
After you deploy the SteelHeads and perform the initial configuration, you can use the features described in this section to deliver an optimal data protection deployment. This section includes the following data protection features:
Adaptive Data Streamlining Feature SettingsCPU SettingsBest Practices for Data Streamlining and CompressionMX-TCP SettingsSteelHead WAN Buffer SettingsRouter WAN Buffer SettingsYou can configure the SteelHead features relevant to data protection in the Management Console in the Optimization > Data Replication: Performance page.
Figure 18‑2. Performance Page Data Streamlining Features
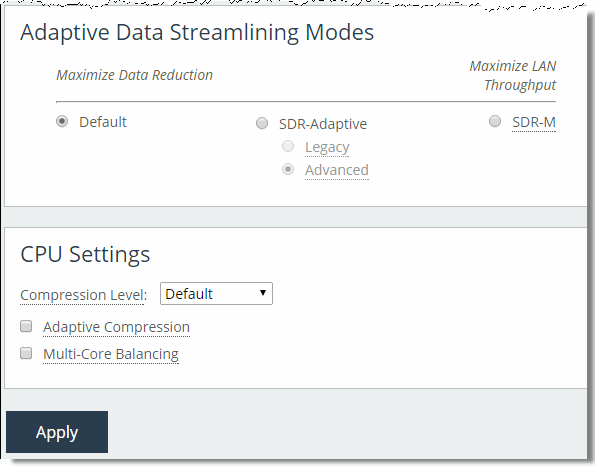
Adaptive Data Streamlining Feature Settings
Adaptive data streamlining provides you with the ability to fine tune the data streamlining capabilities, and enables you to obtain the right balance between optimal bandwidth reduction and optimal throughput.
The following table describes the adaptive data streamlining settings.
Adaptive Data Streamlining Setting | Benefit | Description |
Default SDR/Classic Data Streamlining | Best data reduction | By default, SteelHeads use their disk-based RiOS data store to find data patterns that traverse the network. Previously seen data patterns do not traverse the network in their fully expanded form. Instead, a SteelHead sends a unique identifier for the data to its peer SteelHead, which sends the fully expanded data. In this manner, data is streamlined over the WAN because unique content only traverses the link once. |
Turbo Data Streamlining | Best end-to-end throughput | Turbo SDR is available only on SteelHead DX, and is the default data streamlining mode for that platform. This mode of SDR is optimized for higher-speed data center-to-data center/data replication workloads, delivering up to 2.5 times higher LAN speed to meet aggressive recovery point and time objectives (RPO/RTO) across larger WAN link capacities (1+ Gbps). For optimal performance, use the same data streamlining mode across all peering SteelHead DX appliances. |
SDR-Adaptive | Good data reduction and LAN-side throughput | Dynamically blends different data streaming modes to enable sustained throughput during periods of high disk/CPU-intensive workloads. Legacy - Monitors disk I/O response times and CPU load, and based on statistical trends, employs a blend of disk-based deduplication and compression-based data reduction techniques. Use caution with the Legacy setting, particularly when optimizing CIFS or NFS with prepopulation. For more information, contact Riverbed Support. Advanced - Monitors disk I/O response times, CPU load, and WAN utilization, and based on statistical trends, employs a blend of disk-based deduplication, memory-based deduplication and compress-based data reduction techniques. |
SDR-M | Excellent LAN-side throughput | Performs data reduction entirely in memory, which prevents the SteelHead from reading and writing to and from the disk. Enabling this option can yield high LAN-side throughput because it eliminates all disk latency. SDR-M is typically the preferred configuration mode for SAN replication environments. SDR-M is most efficient between two identical high-end SteelHead models: for example, 6050 - 6050. When SDR-M is configured between two different SteelHead models, the smaller model limits the performance. When you use RiOS SDR-M, RiOS data store synchronization is not possible because none of the data is written to the disk-based data store. For information about data store synchronization, see RiOS Data Store Synchronization. |
CPU Settings
CPU settings provide you with the ability to balance throughput with the amount of data reduction and balance the connection load. The CPU settings are useful with high-traffic loads to scale back compression, increase throughput, and maximize Long Fat Network (LFN) utilization. This section includes the following topics:
Compression LevelAdaptive CompressionMulticore BalancingCompression Level
The compression level specifies the relative trade-off of LZ data compression for LAN throughput speed. Compression levels 1-9 can be specified for fine-tuning. Generally, a lower number provides faster throughput and slightly less data reduction. Setting the optimal compression level provides greater throughput although maintaining acceptable data reduction.
Riverbed recommends setting the compression to level 1 in high-throughput environments such as data-center-to-data-center replication.
The setting is ignored on SteelHead models that are equipped with hardware compression cards.
Adaptive Compression
The adaptive compression feature detects the LZ data compression performance for a connection dynamically and turns it off (that is, sets the compression level to 0) momentarily if it is not achieving optimal results. Enabling this feature can improve end-to-end throughput in cases where the data streams are not further compressible.
Multicore Balancing
Multicore balancing distributes the load across all CPUs, therefore maximizing throughput. Multicore balancing improves performance in cases where there are fewer connections than the total number of CPU cores on the SteelHead. Without multicore balancing, the processing of a given connection is bound to a single core for the life of the connection. With multicore balancing, even a single connection leverages all CPU cores in the system.
Best Practices for Data Streamlining and Compression
Riverbed recommends the following best practices for data protection scenarios:
For SAN replication environments (especially with high bandwidth), start with a SDR-M setting and deploy the same model SteelHead on each side. If you are using a SteelHead DX, use Turbo SDR for high speed. When replicating database log files, the LZ-only compression level typically provides optimal results because database log files contain few repetitive data sequences that can be deduplicated using RiOS SDR. For replication of email repositories such as Microsoft Exchange and Lotus Notes, select an appropriate mode of SDR. If WAN capacity is a bottleneck to end-to-end throughput, select a mode that delivers the highest levels of data reduction, such as default SDR or SDR-A. If WAN capacity is not the bottleneck, select a less aggressive form of data reduction, such as SDR-M or Turbo SDR.Always set the compression level to 1 in high-throughput data center-to-data center replication scenarios. For more information about best practice guidelines and configuration settings, see
Common Data Protection Deployments.
MX-TCP Settings
Maximum TCP (MX-TCP) enables data flows to reliably reach a designated level of throughput. This is useful in data protection scenarios where either:
a dedicated link is used for data protection traffic. a known percentage of a given link can be fully consumed by data protection traffic. For example, if an EMC SRDF/A replication deployment is using peer 6050 SteelHeads that are connected to a dedicated OC-1 link (50 Mbps), then you can create an MX-TCP class of 50 Mbps on each SteelHead. In this example, SRDF/A uses port 1748 for data transfers.
On both the client and server-side SteelHeads, enter the following commands:
qos shaping interface wan0_0 rate 50000
qos shaping interface wan0_0 enable
qos classification enable
qos classification class add class-name "blast" priority realtime min-pct 99.0000000 link-share 100.0000000 upper-limit-pct 100.0000000 queue-type mxtcp queue-length 100 parent "root"
qos classification rule add class-name "blast" traffic-type optimized destination port 1748 rulenum 1
qos classification rule add class-name "blast" traffic-type optimized source port 1748 rulenum 1 write memory
restart
If you cannot allocate a given amount of bandwidth for data protection traffic, but you still require high bandwidth, enable High-Speed TCP (HS-TCP) on peer SteelHeads.
To configure MX-TCP, you must enable advanced outbound QoS on the SteelHead. For more information, see
MX-TCP.
For information about fat pipes, see
Underutilized Fat Pipes. For information about MX-TCP, see
MX-TCP.
For more information about MX-TCP as a transport streaming lining mode, see
Overview of Transport Streamlining.
SteelHead WAN Buffer Settings
In all data protection scenarios, set the SteelHead WAN buffers to at least 2 x BDP. For example, if NetApp SnapMirror traffic is using a dedicated OC-1 link (50 Mbps) with 30 ms of latency (60 ms round-trip time) between sites, then set the SteelHead WAN-side buffers to:
2*BDP = 2 * 50 Mb/s * 1,000,000 b/Mb * 60 ms * (1/1000) s/ms * (1/8) Bytes/bit = 750,000 Bytes
On all SteelHeads in this environment that send or receive the data protection traffic, enter the following commands:
protocol connection wan send def-buf-size 750000
protocol connection wan receive def-buf-size 750000
write memory
restart
Router WAN Buffer Settings
In environments where a small number of connections are transmitting high-throughput data flows, you must increase the WAN-side queues on the router to the BDP.
For example, consider an OC-1 link (50 Mbps) with 60 ms latency (RTT):
BDP = 50 Mbps * 1,000,000 b/Mb * 60 ms * (1/1000) s/ms * (1/8) Bytes/bit * (1/1500) Bytes/packet
= 250 Packets
On the Cisco router, enter the following hold-queue interface configuration command:
hold-queue 250 out
You do not need to increase the router setting when using MX-TCP because MX-TCP moves bottleneck queueing onto the SteelHead. This feature allows WAN traffic to enter the network at a constant rate, eliminating the need for excess buffering on router interfaces.