Data Resilience and Security
This chapter describes security and data resilience deployment procedures and design considerations. It contains the following sections:
Recovering a single Core
If you decide you want to deploy only a single Core, read this section to minimize downtime and data loss when recovering from a Core failure. This section includes the following topics:
Recovering a single physical Core
The Core internal configuration file is crucial to rebuilding your environment in the event of a failure. The possible configuration file recovery scenarios are as follows:
• Up-to-date Core configuration file is available on an external server - When you replace the failed Core with a new Core, you can import the latest configuration file to resume operations. The Edges reconnect to the Core and start replicating the new writes that were created after the Core failed.
In this scenario, you do not need to perform any additional configuration and there is no data loss on the Core and the Edge.
We recommend that you frequently back up the Core configuration file. For details about the backup and restore procedures for device configurations, see the SteelCentral Controller for SteelHead User’s Guide.
Use the following CLI commands to export the configuration file:
enable
configure terminal
configuration bulk export scp://username:password@server/path/to/config
Use the following CLI commands to replace the configuration file:
enable
configure terminal
no service enable
configuration bulk import scp://username:password@server/path/to/config
service enable
• Core configuration file is available but it is not up to date - If you do not regularly back up the Core configuration file, you can be missing the latest information. When you import the configuration file, you retain all data since the last export. The data written to the configuration file after the Core failure to Edges and LUNs are lost. You must manually add the components of the environment that were added after the configuration file was exported.
• No Core configuration file is available - This is the worst-case scenario. In this case you need to build a new Core and reconfigure all Edges as if they were new. All data in the Edges is invalidated, and new writes to Edge LUNs after Core failure are lost. There is no data loss at the Core. If there were applications running at the Edge that cannot handle the loss of most recent data, they need to be recovered from an application-consistent snapshot and backup from the data center.
For more instruction on how to export and import the configuration file, see
Core configuration export and
Core in HA configuration replacement. For general information about the configuration file, see the
SteelFusion Core Management Console User’s Guide.
Recovering a single Core-v
The following recommendation will help to recover from potential failures and disasters and minimize data loss in a Core-v and Edges.
• Configure the Core-v with iSCSI and use VMware HA - VMware HA is a component of the vSphere platform, which provides high availability for applications running in virtual machines. In the event of physical server failure, affected virtual machines are automatically restarted on other production servers. If you configure VMware HA for the Core-v, you have an automated failover for the single Core-v. You must be using iSCSI; do not use with Fibre Channel RDM disks.
• Restore the Core-v from a VM snapshot - We strongly recommend that you do not use this procedure.
The primary reason not to use this procedure is that the configuration file in the Core-v from the snapshot might not be current. If you made any configuration changes since the last VM snapshot, you can lose data if an incorrect Core configuration is suddenly applied to the existing Edge deployment. Using this procedure can also mean LUN snapshots triggered by the Edge might be lost. With SteelFusion 4.2 there is a configuration check performed when a Core-v from an old snapshot is booted up. When the Core-v tries to reconnect to an Edge that has a more recent configuration, an alarm is raised and the Core-Edge connection fails. Prior to SteelFusion 4.2, this check was not available.
Note: Core-v is not compatible with VMware Fault Tolerance (FT).
Edge replacement
In the event of catastrophic failure, you might need to replace the Edge appliance and remap the LUNs. It is usually impossible to properly shut down an Edge LUN and bring it offline because the Edge wants to commit all its pending writes (for the LUN) to the Core. If the Edge has failed, and you cannot successfully bring the LUN offline, you need to manually remove the LUN.
The blockstore is a part of Edge, and if you replace the Edge, the cached data on the failed blockstore is discarded. To protect the Edge against a single point of failure, consider an HA deployment of Edge. For more information, see
Edge high availability.
Use the following procedure for an Edge disaster recovery scenario in which there is an unexpected Edge or remote site failure. This procedure does not include Edge HA.
Note: We recommend that you contact Riverbed Support before performing the following procedure.
To replace the Edge
1. Schedule time that is convenient to be offline (if possible).
2. On the Core, force unmap LUNs from the failed Edge.
3. In the Core Management Console, remove the failed Edge.
4. Add replacement Edge.
You can use the same Edge Identifier.
5. Map LUNs back to the Edge.
Note: When the LUNs are remapped to the replacement Edge, the iSCSI LUN IDs might change. You must rescan or rediscover the LUNs on the ESXi.
You can lose data on the LUNs when writes to the Edge are not committed to the Core. In the case of minimal data loss, it is possible that you can easily recover the LUNs from a crash consistent state, such as with a filesystem check. However, this ease of recovery depends on the type of applications that were using the LUNs. If you have concerns about the data consistency, we recommend that you roll back the LUN to a latest application-consistent snapshot. For details, see
Best practice for LUN snapshot rollback.
Disaster recovery scenarios
This section describes basic SteelFusion appliance disaster scenarios, and includes general recovery recommendations. It includes the following topics:
Keep in mind the following definitions:
• Failover - to switch to a redundant computer server, storage, and network upon the failure or abnormal termination of the production server, storage, hardware component, or network.
• Failback - the process of restoring a system, component, or service previously in a state of failure back to its original, working state.
• Production site - the site in which applications, systems, and storage are originally designed and configured. Also known as the primary site.
• Disaster recovery site - the site that is set up in preparation for a disaster. Also known as the secondary site.
SteelFusion appliance failure—failover
In the case of a failure or a disaster affecting the entire site, we recommend you take the following considerations into account. The exact process depends on the storage array and other environment specifics. You must create thorough documentation of the disaster recovery plan for successful recovery implementation. We recommend that you perform regular testing so that the information in the plan is maintained and up to date.
This sections includes the following topics:
Data center failover
In the event that an entire data center experiences failure or a disaster, you can restore the Core operations assuming you have met the following prerequisites:
• The disaster recovery site has the storage array replicated from the production site.
• The network infrastructure is configured on the disaster recovery site similarly to the production site, enabling the Edges to communicate with Core.
• Core and SteelHeads (or their virtual editions) at the disaster recovery site are installed, licensed, and configured similarly to the production site.
• Ideally, the Core at the disaster recovery site is configured identically to the Core on the production site. You can import the configuration file from Core at the production site to ensure that you have configured both Cores the same way.
Unless the disaster recovery site is designed to be an exact replica of the production site, minor differences are inevitable: for example, the IP addresses of the Core, the storage array, and so on. We recommend that you regularly replicate the Core configuration file to the disaster recovery site and import it into the disaster recovery instance. You can script the necessary adjustments to the configuration to automate the configuration adoption process.
Likewise, the configuration of SteelHeads in the disaster recovery site should reflect the latest changes to the configuration in the production site. All the relevant in-path rules must be maintained and kept up to date.
There are some limitations:
• If you have different LUN IDs in the disaster recovery site than in the production site, you need to reconfigure the Core and all the Edges and deploy them as new. You must know which LUNs belong to which Edge and map them correspondingly. We recommend that you implement a naming convention.
• Even if the data from the production storage array is replicated in synchronous mode, you can assume that there is already committed data to the Edge. The data has not been sent to the production storage, or the data has not been replicated to disaster recovery site yet. This action means that a gap in data consistency can occur if, after the failover, the Edges immediately start writing to the disaster recovery Core. To prevent the data corruption, you need to configure all the LUNs at Edges as new. When you configure Edges as new, this configuration empties out their blockstore, causing data loss of all the writes occurred after a disaster at the production site. To prevent data loss, we recommend that you configure FusionSync. For more information, see
SteelFusion Replication (FusionSync).
• Keep in mind that initially after the recovery, the blockstore on Edges does not have any data in the cache.
Branch office failover
When the Edge in a branch becomes inaccessible from outside the branch office due to a network outage, the operation in the branch office might continue. SteelFusion products are designed with disconnected operations resiliency in mind. If your workflow enables branch office users to operate independently for a period of time (which is defined during the network planning stage and implemented with a correctly sized appliance), the branch office continues as operational and synchronizes with the data center later.
In the case when the branch office is completely lost, or it is imperative for the business to have a service in the branch office online sooner, you can choose to deploy the Edge in another branch or in the data center.
If you chose to deploy an Edge in the data center, we recommend that you remove the LUNs from Core as to prevent data corruption by multiple write access to the LUNs. We recommend that you roll back to a latest application-consistent snapshot. If mostly read access is required to the data projected to the branch office, a good alternative is to temporarily mount a snapshot to a local host. This snapshot enables the data to be accessible to the data center, while the branch office is operating in disconnected-operation mode. Avoiding the failover will also simplify fallback to the production site.
If you chose to deploy Edge in another branch office, follow the steps in
Edge replacement. You must understand that in this scenario, all the uncommitted writes at the branch are not stored. We recommend that you to roll back the LUNs to the latest application-consistent snapshot.
SteelFusion appliance failure—failback
After a disaster is over, or a failure is fixed, you might need to revert the changes and move the data and computing resources to where they were located before the disaster, while ensuring that the data integrity is not compromised. This process is called failback. Unlike the failover process that can occur in a rush, you can thoroughly plan and test the failback process.
This section includes the following topics:
Data center failback
As SteelFusion relies on primary storage to keep the data intact, the Core failback can only follow a successful storage array replication from the disaster recovery site back to the production site. There are multiple ways to perform the recovery; however, we recommend that you use the following method. The process most likely requires a downtime, which you can schedule in advance. We also recommend that you create an application-consistent snapshot and backup prior to performing the following procedure. Perform these steps on one appliance at a time.
To perform the Core failback process
1. Shut down hosts and unmount LUNs.
2. Export the configuration file from the Core at the disaster recovery site.
3. From the Core, initiate taking the Edge offline. This process forces the Edge to replicate all the committed writes to the Core.
4. Remove iSCSI Initiator access from the LUN at the Core.
Data cannot be written to the LUN until the data has become available after the failback completes.
5. Make sure that you replicate the LUN with the storage array from the disaster recovery site back to the production site.
6. On a storage array at the production site, make the replicated LUN the primary LUN.
Depending on a storage array, you might need to create a snapshot, clone, or promote the clone to a LUN—or all the above.
For more information, see the user guide for your storage array. The preferred method is the method that preserves the LUN ID, which might not work for all the arrays. If the LUN ID is going to change, you need to add the LUN as new on first the Core and then on the Edge.
7. If you had to make changes on the disaster recovery site due to a LUN ID change, import the Core configuration file from the disaster recovery site and make the necessary adjustments to IP addresses and so on.
8. Add access to the LUN for Core. If the LUN ID remained the same, the Core at production site begins servicing the LUN instantaneously.
9. At the branch office, check to see if you need to change the Core IP address.
Branch office failback
The branch office failback process is similar to the Edge replacement process. The procedure requires downtime that you can schedule in advance.
If the production LUNs were mapped to another Edge, use the following procedure.
To perform the Edge failback process
1. Shut down hosts and unmount LUNs.
2. Take the LUNs offline from the disaster recovery Edge. This process forces the Edge to replicate all the committed writes to Core.
3. If any changes were made to the LAN mapping configuration, you need to merge the changes during the fallback process. If you need assistance with this process, contact Riverbed Support.
4. Shut down the Edge at the disaster recovery site.
5. Bring up the Edge at the production site.
Keep in mind that after the fallback process is completed, the blockstore on Edges does not have any data in the cache.
If you took out the production LUNs of the Core and used them locally in the data center, shut down hosts and unmount LUNs and then continue the setup process as described in the SteelFusion Core Installation and Configuration Guide.
Best practice for LUN snapshot rollback
When single file restore is impossible or impractical, you can roll back the entire LUN snapshot on the storage array at the data center and projected out to the branch. We recommend the following procedure for a LUN snapshot rollback.
Note: A single file restore is to recover your deleted file from a backup or a snapshot without rolling back the entire file system to a point of time in which a file still existed in the file system. When you use the LUN rollback, everything that was written to (and deleted from) the file system is lost.
To roll back the LUN snapshot
1. Set the LUN offline at the server running at the Edge.
2. Remove iSCSI initiator access from the LUN at the Core.
3. Remove the LUN from the Core.
4. Restore the LUN on the storage array from a snapshot.
5. Add the LUN to the Core.
6. Add iSCSI initiator access for the LUN at Core.
You can now access the LUN snapshot from a server on the Edge.
Keep in mind that after this process is completed, the blockstore on Edges does not have any data in the cache.
Using CHAP to secure iSCSI connectivity
Challenge-Handshake Authentication Protocol (CHAP) is a convenient and well-known security mechanism that can be used with iSCSI configurations. This section provides an overview with an example configuration. It contains the following topics:
Both types of CHAP are supported on Core and Edge.
For more details about configuring CHAP on either Core or Edge, see the corresponding Management Console user’s guide.
Within an iSCSI deployment both initiator and target have their own passwords. In CHAP terminology these are called secrets. These passwords are shared between initiator and target in order for them to authenticate with each other.
One-way CHAP
With one-way CHAP, the iSCSI target (server) authenticates the iSCSI initiator (client).
This process is analogous to logging in to a website. The Initiator needs to provide a username and secret when logging in to the target. The username is usually the IQN (but can be any free-form string) and the password is the target secret.
To configure one-way CHAP in a Core deployment
1. Configure a target secret on the backend storage array portal.
2. Log in to the Core Management Console.
3. Add a CHAP User on the Core.
The username is something descriptive or even the IQN of the Core. For example, username=cuser2. The password is the target secret configured on the backend array.
When the iSCSI initiator on the Core connects to the backend storage array, it uses the credentials from the CHAP user that was created.
Figure: iSCSI portal configuration for one-way CHAP
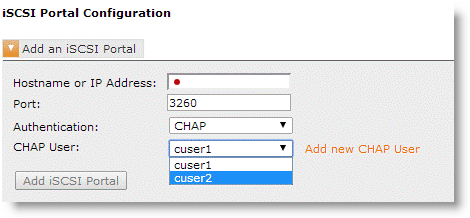
CHAP credentials are created and stored separately. They are then used when the Core initiates an iSCSI session and logs in to the storage array portal.
Mutual CHAP
The difference between one-way CHAP and mutual CHAP is that the iSCSI target authenticates the iSCSI initiator and additionally the iSCSI initiator also authenticates the iSCSI target.
Mutual CHAP incorporates two separate sequences. The first sequence is the iSCSI target authenticating the iSCSI initiator and is the exact same procedure as for one-way CHAP. The second sequence is the initiator authenticating the target, which is the reverse of the previous authentication procedure.
To configure mutual CHAP in a Core deployment
1. Configure an initiator CHAP User on the Core Management Console.
For example: username = cuser1 and password = abcd1234
The Core now requires all iSCSI targets to specify the password (or secret) abcd1234 before the target is trusted by the Core.
Figure: iSCSI initiator configuration for mutual CHAP
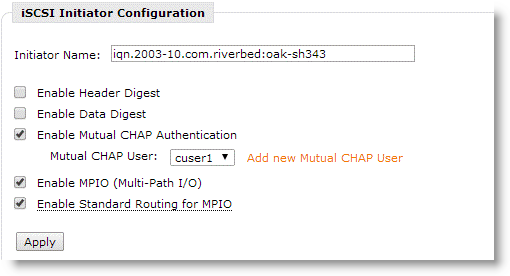
3. On the backend storage array, add the CHAP user details from the Core.
In this example, the storage array CHAP user has username=cuser1 and password=abcd1234.
The target now knows the secret (username and password) of the initiator.
4. On the backend storage array, configure a target CHAP user.
For example: username = cuser2 and password = wxyz5678
5. Log in to the Core Management Console and add the target CHAP User on the Core.
In this example: username = cuser2 and password = wxyz5678
Mutual CHAP configuration is now complete.
When adding the portal of the backend storage array to the Core configuration, select the target CHAP user (cuser2).
When the iSCSI initiator of the Core connects to the iSCSI target of the backend storage array, it uses the credentials from the CHAP user (cuser2) that you created.
Because of mutual CHAP, the iSCSI target uses the credentials cuser1/abcd1234 to connect to the iSCSI initiator of the Core.
At-rest and in-flight data security
For organizations that require high levels of security or face stringent compliance requirements, Edge provides data at-rest and in-flight encryption capabilities for the data blocks written on the blockstore cache. This section includes the following topics:
Supported encryption standards include AES-128, AES-192, and AES-256. The keys are maintained in an encrypted secure vault. In 2003, the United States government declared a review of the three algorithm key lengths to see if they were sufficient for protection of classified information up to the secret level. Top secret information requires 192-bit or 256-bit keys.
The vault is encrypted by AES with a 256-bit key and a 16-byte cipher, and you must unlock it before the blockstore is available. The secure vault password is verified upon every power up of the appliance, assuring that the data is confidential in case the Edge is lost or stolen.
Initially, the secure vault has a default password known only to the RiOS software so the Edge can automatically unlock the vault during system startup. You can change the password so that the Edge does not automatically unlock the secure vault during system startup and the blockstore is not available until you enter the password.
When the system boots, the contents of the vault are read into memory, decrypted, and mounted (through EncFS, a FUSE-based cryptographic file system). Because this information is only in memory, when an appliance is rebooted or powered off, the information is no longer available and the in-memory object disappears. Decrypted vault contents are never persisted on disk storage.
We recommend that you keep your secure vault password safe. Your private keys cannot be compromised, so there is no password recovery. In the event of a lost password, you can reset the secure vault only after erasing all the information within the secure vault.
To reset a lost password
• From either Edge appliance, enter the following CLI commands:
> enable
# configure terminal
(conf)# secure-vault clear
When you use the secure-vault clear command, you lose the data in the blockstore if it was encrypted. You then need to reload or regenerate the certificates and private keys.
Note: The Edge blockstore encryption is the same mechanism that is used in the RiOS data store encryption. For more information, see the security information in the SteelHead Deployment Guide.
Configuring data encryption requires extra CPU resources and might affect performance. We recommend blockstore encryption only if you require a high level of security or dictated by compliance requirements.
Enable data at-rest blockstore encryption
The following example shows how to configure blockstore encryption on an Edge. The commands are entered on the Core at the data center.
To configure blockstore encryption on the Edge
1. From the Core, enter the following commands:
> enable
# configure
(config) # edge id <edge-identifier> blockstore enc-type <AES_128 | AES_192 | AES_256 | NONE>
2. To verify whether encryption has been enabled on the Edge, enter the following commands:
> enable
# show edge id <edge-identifier> blockstore
Write Reserve : 10%
Encryption type : AES_256
You can do the same procedure in the Core Management Console by choosing Configure > Manage: SteelFusion Edges.
Figure: Adding blockstore encryption
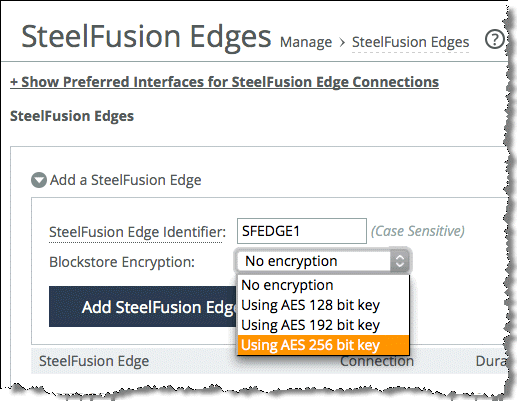
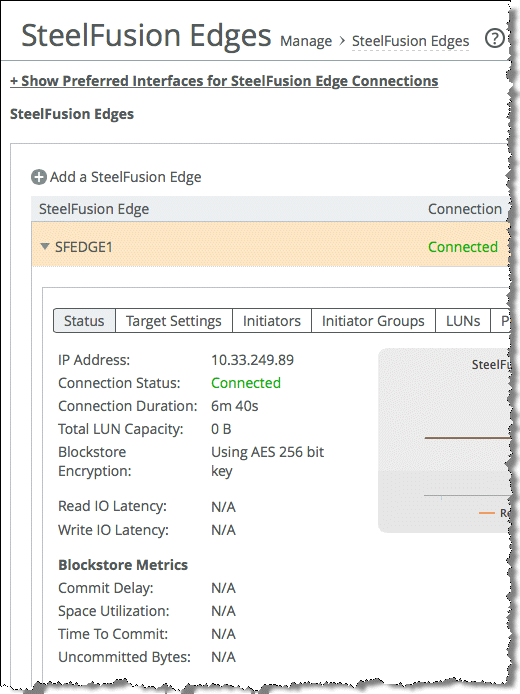
To verify whether encryption is enabled on your Edge appliance, look at the Blockstore Encryption field on your Edge status window as shown in
Figure: Verify blockstore encryption.
Figure: Verify blockstore encryption
Enable data in-flight secure peering encryption
SteelFusion Rdisk protocol operates on clear text and there is a possibility that remote branch data can be exposed to hackers during transfer over the WAN. To counter this exposure, the Edge provides data in-flight encryption capabilities when the data blocks are asynchronously propagated to the data center LUN.
You can use secure peering between the Edge and the data center SteelHead to create a secure SSL channel and protect the data in-flight over the WAN. For more information about security and SSL, see the SteelHead Deployment Guide and the SteelHead Deployment Guide - Protocols.
Clearing the blockstore contents
Under normal conditions, if you select Offline on the Core for a particular LUN, the contents of the blockstore on the corresponding Edge is synchronized and then cleared.
However, there can be a situation in which it is necessary to make sure the entire contents of the blockstore on an Edge is erased to a military grade level. While you can achieve this level of deletion, it involves the use of commands not normally available for general use. To ensure the correct procedures are followed, please open a support case with Riverbed Support.
Edge network communication
In a location in which you have deployed Edge, there can be a requirement to keep track of the ports and protocols used with the various interfaces that are active. The following table provides you with a general list of devices and ports, including a description of what the communication is related to.
Source Device | Source port | Destination device | Destination port | Protocol | Description |
Edge primary interface | Any | Core | 7950-7955 | TCP | BlockStream |
Edge primary interface | Any | Core | 7970 | TCP | SteelFusion management |
SCC and other management hosts | Any | Edge primary interface | 22,80,443 | TCP | Edge management |
VSP management hosts | Any | Through the Edge primary interface (using virtual IP) | | | ESXi management |
VSP management hosts | Any | Through Edge primary interface (using VM management IP, vm_pri) | 3389 | TCP | RDP to remote VM |
vSphere client machine | Any | Through the Edge primary interface (using virtual IP) | 22, 80, 443, 902, 903, 9443 | TCP, UDP | ESXi management |
Edge primary interface (using VM management IP, vm_pri) | Any | vSphere client machine | 22, 80, 443, 902, 903 | TCP, UDP | VM management |
Edge in-path interface | Any | Core | Any | TCP, UDP, ICMP | WAN optimization |
Additional security best practices
For additional advice and guidance on appliance security in general, see the SteelHead Deployment Guide. The guide includes suggestions on restricting web-based access, the use of role-based accounts, creation of login banners, alarm settings, and so on, which you can apply in principle to SteelFusion Edge appliances.
Related information
• SteelFusion Core Management Console User’s Guide
• SteelFusion Edge Management Console User’s Guide
• SteelFusion Core Installation and Configuration Guide
• SteelFusion Command-Line Interface Reference Manual
• SteelHead Deployment Guide
• Riverbed Splash at https://splash.riverbed.com/community/product-lines/steelfusion