SteelFusion Appliance High-Availability Deployment
This chapter describes high-availability (HA) deployments for the Core and the Edge. It includes the following sections:
Overview of storage availability
Applications of any type that read and write data to and from storage can suffer from three fundamental types of availability loss:
• Loss of storage
• Loss of access to the storage
• Loss of the data residing on the storage
As with a typical storage deployment, you might consider data HA and redundancy as a mandatory requirement rather than an option. Applications accessing data are always expecting the data, and the storage that the data resides on, to be available at all times. If for some reason the storage is not available, then the application ceases to function.
Storage availability is the requirement to protect against loss of access to stored data or loss of the storage in which the data resides. Storage availability is subtly different from data loss. In the case of data loss, whether due to accidental deletion, corruption, theft, or another event, you can recover the data from a snapshot, backup, or some other form of archive. If you can recover the lost data, it means that you previously had a process to copy data, either through snapshot, backup, replication, or another data management operation.
In general, the net effect of data loss or lack of storage availability is the same—loss of productivity. But the two types of data loss are distinct and addressed in different ways.
The subject of data availability in conjunction with the SteelFusion product family is documented in a number of white papers and other documents that describe the use of snapshot technology and data replication as well as backup and recovery tools. To read the white papers, go to
https://support.riverbed.com.The following sections discuss how to make sure you have storage availability in both the Core and Edge deployments.
Note: Core HA and Edge HA are independent from each other. You can have Core HA with no Edge HA, and vice versa.
Core high availability
This section describes HA deployments for the Core. It contains the following topics:
You can deploy a Core as a single, stand-alone implementation; however, we strongly recommend that you always deploy the Core as pairs in an HA cluster configuration. The storage arrays and the storage area network (SAN) the Core attaches to are generally deployed in a redundant manner.
For more information about Core HA clusters, see
Core HA concepts. For more information about single-appliance implementation, see
Single-appliance deployment.
In addition to the operational and hardware redundancy provided by the deployment of Core clusters, you can also cater to network redundancy. When connecting to a SAN using iSCSI, Cores support the use of multiple path input and output (multipath I/O or MPIO).
MPIO uses two separate network interfaces on the Core to connect to two separate iSCSI portals on the storage array. The storage array must support MPIO. Along with network redundancy, MPIO enables for scalability by load-balancing storage traffic between the Core and the storage array.
Note: MPIO is also supported on Edge deployments in which the LUNs available from Edge are connected to servers operating in the branch office.
For more information about MPIO with Core, see
Core with MPIO. For information about MPIO with Edge, see
SteelFusion Edge with MPIO.
For information about setting up Core HA with FusionSync (SteelFusion Replication), see .
Core with MPIO
MPIO ensures that a failure of any single component (such as a network interface card, switch, or cable) does not result in a communication problem between the Core and the storage array.
Figure: Basic topology for Core MPIO shows an example of a basic Core deployment using MPIO. The figure shows a single Core with two network interfaces connecting to the iSCSI SAN. The SAN has a simple
full mesh network design enabling each Core interface to connect to each iSCSI portal on the storage array.
Figure: Basic topology for Core MPIO
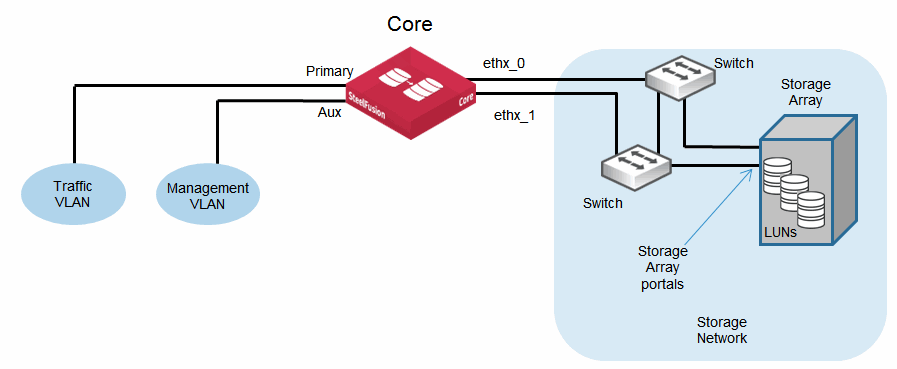
When you configure a Core for MPIO, by default it uses a round-robin policy for any read operations to the LUNs in the storage array. Write operations use a fixed-path policy, only switching to an alternative path in the event of a path or portal failure.
For more details about MPIO configuration for the Core, see the SteelFusion Core Management Console User’s Guide.
Core HA concepts
A pair of Cores deployed in an HA-failover cluster configuration are active-active. Each Core is the primary to itself and secondary to its peer. Both peers in the cluster are attached to storage in the data center. But individually they each are responsible for projecting one or more LUNs to one or more Edge appliances in branch locations.
Each Core is configured separately for the LUNs and the Edges it is responsible for. When you enable failover on the Core, you can choose which individual LUNs are part of the HA configuration. By default in a Core HA deployment, all LUNs are automatically configured for failover. You can selectively disable failover on an individual LUN basis in the Management Console by choosing Configure > Manage: LUNs. LUNs that are not included in the HA configuration are not available at the Edge if the Core fails.
As part of the HA deployment, you configure each Core with the details of its failover peer. This deployment comprises two IP addresses of network interfaces called failover interfaces. These interfaces are used for heartbeat and synchronization of the peer configuration. After the failover interfaces are configured, the failover peers use their heartbeat connections (failover interfaces) to share the details of their storage configuration. This information includes the LUNs they are responsible for and the Edges they are projecting the LUNs to.
If either peer fails, the surviving Core can take over control of the LUNs from the failed peer and continue projecting them to the Edges.
Core HA failover is triggered at the Core level. If an Edge loses connection to its primary Core, but still has connectivity to the secondary Core, no failover occurs. No failover occurs because both Cores continue to detect each other's heartbeat through the failover interfaces. The Edge enters a disconnected operations state as normal and saves write operations to the blockstore until connectivity to the primary Core is restored.
Note: Make sure that you size both failover peers correctly so that they have enough capacity to support the other Core storage in the event of a peer failure. If the surviving peer does not have enough resources (CPU and memory), then performance might degrade in a failure situation.
After a failed Core has recovered, the failback is automatic.
Configuring HA for Core
This section describes best practices and the general procedure for configuring high availability between two Cores.
Note: Core HA configuration is independent of Edge HA configuration.
This section contains the following topics:
Cabling and connectivity for clustered Cores
Figure: Basic topology for Core HA shows an example of a basic HA topology including details of the different network interfaces used.
Note: Use crossover cables for connecting ports in clustered Cores.
Figure: Basic topology for Core HA
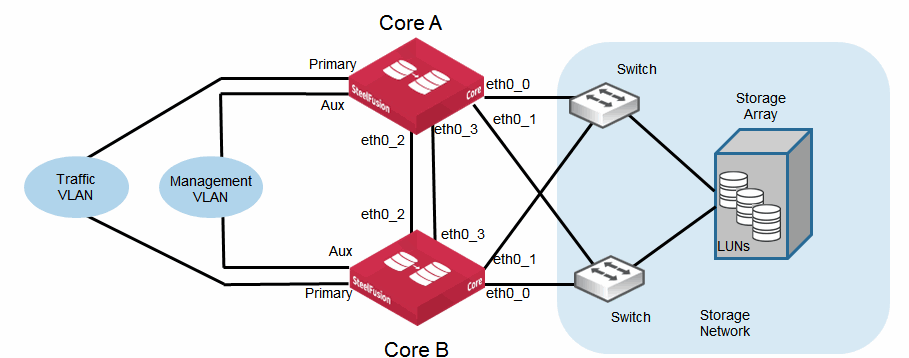
In the scenario shown in
Figure: Basic topology for Core HA, both Cores (Core A and Core B) connect to the storage array through their respective eth0_0 interfaces. Notice that the eth0_1 interfaces are also used in this example for MPIO or additional SAN connectivity. The Cores communicate between each other using the failover interfaces that are configured as eth0_2 and eth0_3. Their primary interfaces are dedicated to the traffic VLAN that carries data to and from Edge appliances. The auxiliary interfaces are connected to the management VLAN and used to administer the Cores. You can administer a Core from any of its configured interfaces assuming they are reachable. Use the AUX interface as a dedicated management interface rather than using one of the other interfaces that might be in use for storage data traffic.
When it is practical, use two dedicated failover interfaces for the heartbeat. Connect the interfaces through crossover cables and configure them using private IP addresses. This connection minimizes the risk of a split-brain scenario in which both Core peers consider the other to have failed. Directly connected, dedicated interfaces might not be possible for some reason. If the dedicated connections need to go through some combinations of switches and/or routers, they must use diverse paths and network equipment to avoid a single point of failure.
If you cannot configure two dedicated interfaces for the heartbeat, then an alternative is to specify the primary and auxiliary interfaces. Consider this option only if the traffic interfaces of both Core peers are connecting to the same switch or are wired so that a network failure means one of the Cores loses connection to all Edge appliances.
You can configure Cores with additional NICs to provide more network interfaces. These NICs are installed in PCIe slots within the Core. Depending on the type of NIC you install, the network ports could be 1-Gb Ethernet or 10-Gb Ethernet. In either case, you can use the ports for storage or heartbeat connectivity. The ports are identified as ethX_Y where X corresponds to the PCIe slot (from 1 to 5) and Y refers to the port on the NIC (from 0 to 3 for a four-port NIC and from 0 to 1 for a two-port NIC).
For more information about Core ports, see
Interface and port configuration.
You can use these additional interfaces for iSCSI traffic or heartbeat. Use the same configuration guidance as already described above for the eth0_0 to eth0_3 ports.
Under normal circumstances the heartbeat interfaces need to be only 1 Gb; therefore, it is simpler to use eth0_2 and eth0_3 as already described. However, there can be a need for 10-Gb connectivity to the iSCSI SAN, in which case you can use an additional NIC with 10-Gb ports in place of eth0_0 and eth0_1. If you install the NIC in PCIe slot 1 of the Core, then the interfaces are identified as eth1_0 and eth1_1 in the Core Management Console.
When using multiple interfaces for storage connectivity in an HA deployment, all interfaces should match in terms of their capabilities. Therefore, avoid mixing combinations of 1 Gb and 10 Gb for storage connectivity.
Configuring failover peers
You configure Core high availability by choosing Configure > Failover: Failover Configuration. To configure failover peers for Core, you need to provide the following information for each of the Core peers:
• The IP address of the peer appliance
• The local failover interface through which the peers exchange and monitor heartbeat messages
• An additional IP address of the peer appliance
• An additional local failover interface through which the peers exchange and monitor heartbeat messages
Figure: Core HA failover interface design shows an example deployment with failover interface IP addresses. You can configure any interface as a failover interface, but to maintain some consistency we recommend that you configure and use eth0_2 and eth0_3 as dedicated failover interfaces.
Figure: Core HA failover interface design
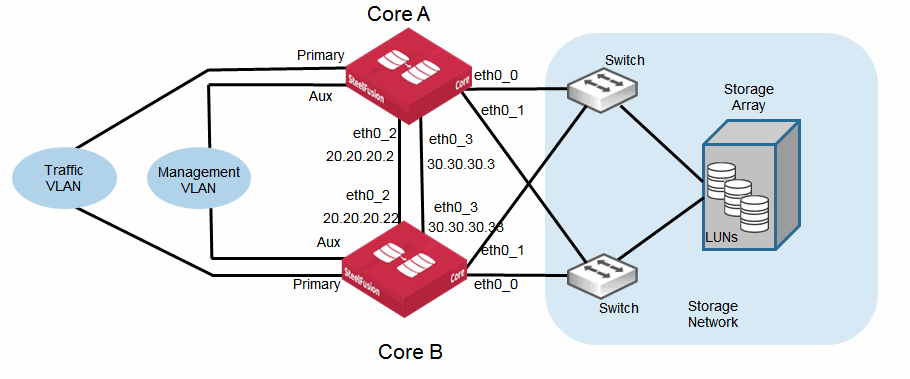
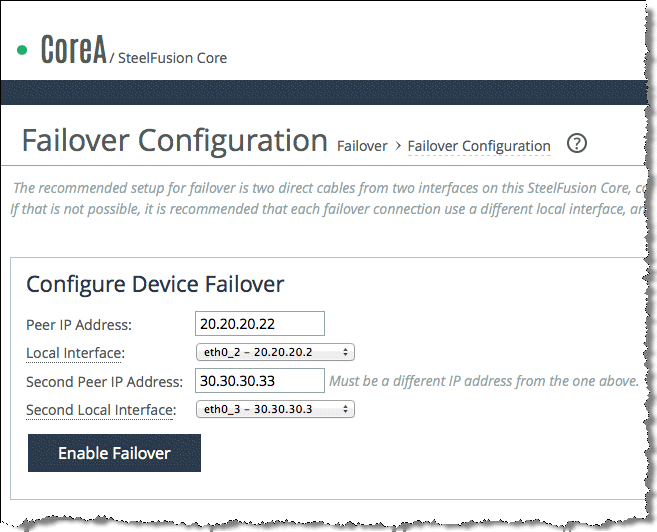
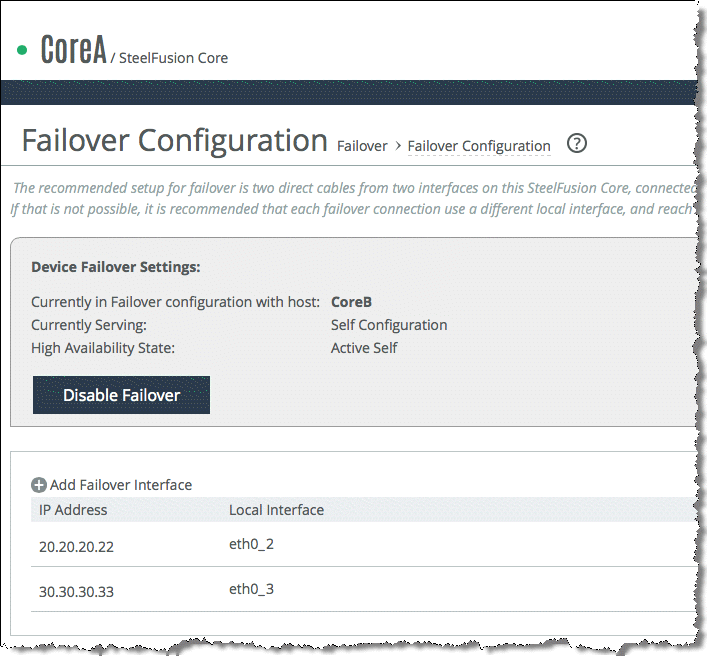
Figure: Core Failover Configuration page shows the Failover Configuration page for Core A in which the peer is Core B. The failover interface IP addresses are 20.20.20.22 and 30.30.30.33 through interfaces eth0_2and eth0_3 respectively. The page shows eth0_2 and eth0_3 selected from the Local Interface drop-down list and the IP addresses of Core B interfaces are completed. Notice that in the Configuration page you can select the interface you want to use for connections from the failover peer Edge appliances. This example shows that the primary interface has been chosen.
Figure: Core Failover Configuration page
After you click
Enable Failover, the Core attempts to connect through the failover interfaces sending the storage configuration to the peer. If successful, you see the Device Failover Settings as shown in
Figure: Core HA Failover Configuration page 2.
Figure: Core HA Failover Configuration page 2
After the Core failover has been successfully configured, you can log in to the Management Console of the peer Core and view its Failover Configuration page.
Figure: Core HA Peer Failover configuration page 3 shows that the configuration page of the peer is automatically configured with the relevant failover interface settings from the other Core.
Figure: Core HA Peer Failover configuration page 3
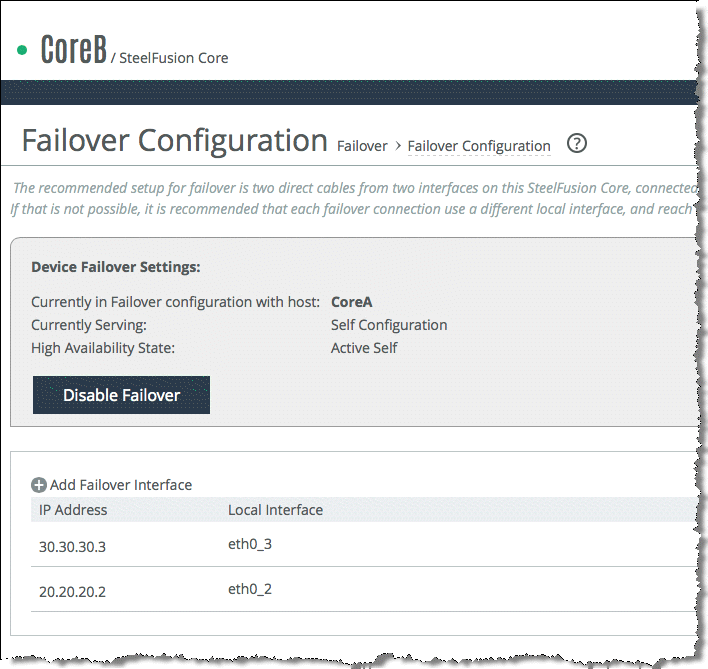
Even though the relevant failover interfaces are automatically configured on the peer, you must configure the peer Preferred Interfaces for Edge Connections. By default, the primary interface is selected.
For more information about HA configuration settings, see the SteelFusion Core Management Console User’s Guide.
In the Core CLI, you can configure failover using the device-failover peer and device-failover peerip commands. To display the failover settings use the show device-failover command.
For more information, see the SteelFusion Command-Line Interface Reference Manual.
If the failover configuration is not successful, then details are available in the Core log files and a message is displayed in the user interface. The failure can be for any number of different reasons. Some examples, along with items to check, are as follows:
• Unable to contact peer - Check the failover interface configurations (IP addresses, interface states and cables).
• Peer is already configured as part of a failover pair - Check that you have selected the correct Core.
• The peer configuration includes one or more LUNs that are already assigned to the other Core in the failover pair - Check the LUN assignments and correct the configuration.
• The peer configuration includes one or more Edge appliances that are already assigned to the other Core in the failover pair - Check the Edge assignments and correct the configuration.
After the failover configuration is complete and active, the configurations of the two peers in the cluster are periodically exchanged through a TCP connection using port 7971 on the failover interfaces. If you change or save either Core configuration, the modified configuration is sent to the failover peer. In this way, each peer always has the latest configuration details of the other.
You configure any Edge that is connecting to a Core HA configuration with the primary Core details (hostname or IP). After connected to the primary Core, the Edge is automatically updated with the peer Core information. This information ensures that during a Core failover situation in which an Edge loses its primary Core, the secondary Core can signal the Edge that it is taking over. The automatic update also minimizes the configuration activities required at the Edge regardless of whether you configure Core HA or not.
Accessing a failover peer from a Core
When you configure a Core for failover with a peer Core, all storage configuration pages include an additional feature that enables you to access and modify settings for both the current appliance you are logged in to and its failover peer.
You can use a drop-down list below the page title to select Self (the current appliance) or Peer. The page includes the message Device Failover is enabled, along with a link to the Failover Configuration page.
Figure: Failover-enabled feature on Storage Configuration pages shows two sample iSCSI Configuration pages: one without HA enabled and one with HA enabled, showing the drop-down list.
Figure: Failover-enabled feature on Storage Configuration pages

Note: Because you can change and save the storage configuration settings for the peer in a Core HA deployment, ensure that any configuration changes are made for the correct Core.
Additionally, the Core storage report pages include a message that indicates when device failover is enabled, along with a link to the Failover Configuration page. You must log in to the peer Core to view the storage report pages for the peer.
SCSI reservations between Core and storage arrays
When you deploy two Cores as failover peers it is an active-active configuration. Each Core is primarily responsible for the LUNs that is has been configured with. As part of the HA configuration, some, if not all, of the LUNs are enabled for failover. During a failover scenario, the surviving peer takes over the LUNs of the failed peer that have been enabled for failover. To be able to take over the LUNs in a safe and secure way, the Core makes use of SCSI reservations to the back-end storage array.
SCSI reservations are similar in concept to client file-locking on a file server. The SCSI reservation is made by the initiator and provides a way to prevent other initiators from making changes to the LUN. Prior to making a reservation, the initiator must first make a Register request for the LUN. This request is in the form of a Reservation key. After the storage array acknowledges the reservation key, the reservation is made.
The Core registers requests to the storage array for each LUN it is responsible for. It then makes persistent reservations for each LUN. A persistent reservation is maintained across power failures and reboots of the initiator and target devices. It can only be cleared by the initiator releasing the reservation, or an initiator preempting the reservation.
In a Core HA deployment, each peer knows the LUNs that are enabled for failover on the other peer. Because of knowledge, in a failover scenario, a surviving peer can send the storage array a request to read current reservations for each of the relevant LUNs. The storage array responds with the reservation keys of the failed Core. The surviving peer sends a preempt reservation request for each LUN that it needs to take control of from the failed peer. The preempt reservation request comprises the reservation key of the failed peer and its own registration key for each LUN.
Because of the requirement to transfer persistent reservations between peer Cores during a failover or failback scenario, your storage array might need to be explicitly configured to allow this transfer. The actual configuration steps required depend on the storage array vendor but might involve some type of setting for simultaneous access. For details, consult relevant documentation of the storage array vendor.
Failover states and sequences
At the same time as performing their primary functions associated with projecting LUNs, each Core in an HA deployment is using its heartbeat interfaces to check if the peer is still active. By default, the peers check each other every 3 seconds through a heartbeat message. The heartbeat message is sent through TCP port 7972 and contains the current state of the peer that is sending the message.
The state is one of the following:
• ActiveSelf - The Core is healthy, running its own configuration and serving its LUNs as normal. It has an active heartbeat with its peer.
• ActiveSolo - The Core is healthy but the peer is down. It is running its own configuration and that of the failed peer. It is serving its LUNs and also the LUNs of the failed peer.
• Inactive - The Core is healthy but has just started up and cannot automatically transition to ActiveSolo or ActiveSelf. Typically this state occurs if both Cores fail at the same time. To complete the transition, you must manually activate the correct Core. For more information, see
Recovering from failure of both Cores in HA configuration.
• Passive - The default state when Core starts up. Depending on the status of the peer, the Core state transitions to Inactive, ActiveSolo, or ActiveSelf.
If there is no response from three consecutive heartbeats, then the secondary Core declares the primary failed and initiates a failover. Both Cores in an HA deployment are primary for their own functions and secondary for the peer. Therefore, whichever Core fails, it is the secondary that takes control of the LUNs from the failed peer.
After the failover is initiated, the following sequence of events occurs:
1. The secondary Core preempts a SCSI reservation to the storage array for all of the LUNs that the failed Core is responsible for in the HA configuration.
2. The secondary Core contacts all Edges that are being served by the failed (primary) Core.
3. The secondary Core begins serving LUNs to the Edges.
The secondary Core continues to issue heartbeat messages. Failback is automatic after the failed Core comes back online and can send its own heartbeat messages again. The failback sequence is effectively a repeat of the failover sequence with the primary Core going through the three steps described above.
Recovering from failure of both Cores in HA configuration
You can have a scenario in which both Cores in an HA configuration fail at the same time; for example, a major power outage. In this instance there is no opportunity for either Core to realize that its peer has failed.
When both Core appliances reboot, each peer knows that itself has failed but does not have status from the other to say that it had been in an ActiveSolo state. Therefore, both Cores remain in Inactive state. This state ensures that neither Core is projecting LUNs until you manually activate the correct Core. To activate the correct Core, choose Configure > Failover: Failover Configuration and select Activate Config.
After you activate the correct Core, it transitions to ActiveSolo. Both Core appliances transition to ActiveSelf.
Removing Cores from an HA configuration
This section describes the procedure for removing two Cores from their failover configuration.
To remove Cores from an HA configuration (basic steps)
1. Force one of the Cores into a failed state by stopping its service.
2. Disable failover on the other Core.
3. Start the service on the first Core again.
4. Disable the failover on the second Core.
You can perform these steps using either the Management Console or the CLI.
Figure: Example configuration of Core HA deployment shows an example configuration.
Figure: Example configuration of Core HA deployment
1. From the Management Console of Core A, choose Settings > Maintenance: Service.
2. Stop the Core service.
3. From the Management Console of Core B, choose Configure > Failover: Failover Configuration.
4. Click Disable Failover.
5. Return to the Management Console of Core A, and choose Settings > Maintenance: Service.
6. Start the Core service.
7. From the Management Console of Core A, choose Configure > Failover: Failover Configuration.
8. Click Disable Failover.
9. Click Activate Local Configuration.
Core A and Core B are no longer operating in an HA configuration.
1. Connect to the CLI of Core A and enter the following commands to stop the Core service:
enable
configure terminal
no service enable
2. Connect to the CLI of Core B and enter the following commands to clear the local failover configuration:
enable
configure terminal
device-failover peer clear
write memory
3. Return to the CLI of Core A and enter the following commands to start the Core service, clear the local failover configuration, and return to nonfailover mode:
enable
configure terminal
service enable
device-failover peer clear
device-failover self-config activate.
write memory
Core A and Core B are no longer operating in an HA configuration.
Edge high availability
The SteelFusion Edge appliance presents itself as an iSCSI target for storage to application servers in one or both of the following modes:
• Storage is resident in the RiOS node and is accessed through iSCSI internally to the appliance by the hypervisor node. In this mode, the hypervisor running in the hypervisor node is acting as the iSCSI initiator.
• Storage is accessed through an iSCSI initiator on a separate server or hypervisor host that is external to the SteelFusion Edge.
In either deployment mode, in the unlikely event of failure or a scheduled loss of service due to planned maintenance, you might need an alternative way to access the storage and ensure continued availability of services in the branch. Deploying two SteelFusion Edges in a high availability (HA) configuration enables this access.
This section describes HA deployments for the SteelFusion Edge appliance. It contains the following topics:
Note: This guide requires you to be familiar with the SteelFusion Edge Management Console User’s Guide.
Using the correct Interfaces for SteelFusion Edge deployment
This section reviews the network interfaces on SteelFusion Edge and how you can configure them. For more information about SteelFusion Edge network interface ports, see
Edge appliances ports.
By default, all SteelFusion Edge appliances are equipped with the following physical interfaces:
• Primary, Auxiliary, eth0_0, eth0_1, lan1_0, wan1_0, lan1_1, wan1_1 - These interfaces are owned and used by the RiOS node in SteelFusion Edge.
• gbe0_0, gbe0_1, gbe0_2, gbe0_3 - These interfaces are owned and used by the hypervisor node in SteelFusion Edge.
Traditionally in a SteelFusion Edge appliance, the LAN and WAN interface pairs are used by the RiOS node as an in-path interface for WAN optimization. The primary and auxiliary interfaces are generally used for management and other services.
In a SteelFusion Edge HA deployment, the eth0_0 and eth0_1 interfaces are used for the heartbeat interconnect between the two SteelFusion Edge HA peers. If there is only a single SteelFusion Edge deployed in the branch, then you can use eth0_0 and eth0_1 as data interfaces for iSCSI traffic to and from servers in the branch that are external to the SteelFusion Edge.
While there are many additional combinations of port usage, you can generally expect that iSCSI traffic to and from external servers in the branch use the primary interface. Likewise, the Rdisk traffic to and from the Core uses the primary interface by default and is routed through the SteelFusion Edge in-path interface. The Rdisk traffic gains some benefit from WAN optimization. Management traffic for the SteelFusion Edge typically uses the auxiliary interface.
For the hypervisor node, you can use the gbe0_0 to gbe0_3 interfaces for general purpose LAN connectivity within the branch location. These interfaces enable clients to access services running in virtual machines installed on the hypervisor host.
Figure: Basic interface configuration for SteelFusion Edge with external servers shows a basic configuration example for SteelFusion Edge deployment. The SteelFusion Edge traffic flows for Rdisk and iSCSI traffic are shown.
Figure: Basic interface configuration for SteelFusion Edge with external servers
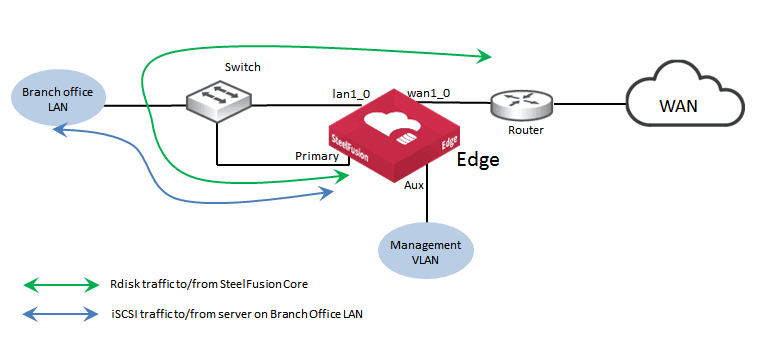
Figure: Basic Interface Configuration for SteelFusion Edge with Servers Hosted in Hypervisor Node shows no visible sign of iSCSI traffic because the servers that are using the LUNs projected from the data center are hosted within the hypervisor node resident on the SteelFusion Edge. Therefore, all iSCSI traffic is internal to the appliance. If a SteelFusion Edge deployment has no WAN optimization requirement, then you can connect the primary interface directly to the lan0_1 interface using a crossover cable, enabling the Rdisk traffic to flow in and out of the primary interface. In this case, management of the appliance is performed through the auxiliary interface. Clients in the branch access the servers in the hypervisor node by accessing through the network interfaces gbe0_0 to gbe0_3 (not shown in
Figure: Basic Interface Configuration for SteelFusion Edge with Servers Hosted in Hypervisor Node).
Figure: Basic Interface Configuration for SteelFusion Edge with Servers Hosted in Hypervisor Node
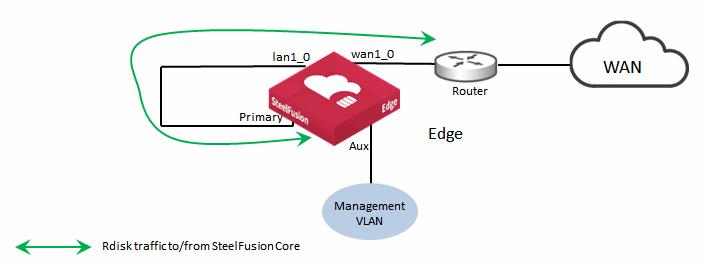
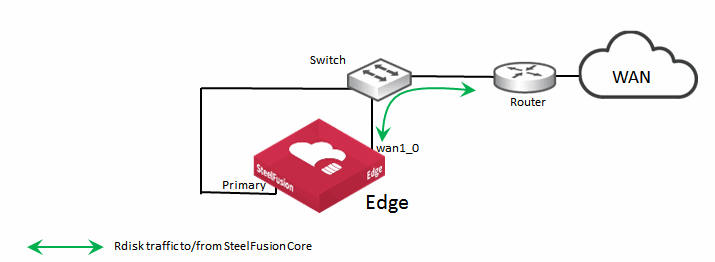
Figure: Alternative Interface Configuration for SteelFusion Edge with Servers Hosted in Hypervisor Node shows a minimal interface configuration. The iSCSI traffic is internal to the appliance in which the servers are hosted within the hypervisor node. Because you can configure SteelFusion Edge to use the in-path interface for Rdisk traffic, this configuration makes for a very simple and nondisruptive deployment. The primary interface is still connected and can be used for management. Client access to the servers in the hypervisor node is through the gbe0_0 to gbe0_3 network interfaces (
Figure: Alternative Interface Configuration for SteelFusion Edge with Servers Hosted in Hypervisor Node).
We do not recommend this type of deployment for permanent production use, but it can be suitable for a proof of concept in lieu of a complicated design.
Figure: Alternative Interface Configuration for SteelFusion Edge with Servers Hosted in Hypervisor Node
We recommend that you make full use of all the connectivity options available in the appliance for production deployments of SteelFusion Edge. Careful planning can ensure that important traffic, such as iSCSI traffic to external servers, Rdisk to and from the Core, and blockstore synchronization for high availability, are kept apart from each other. This separation helps with ease of deployment, creates a more defined management framework, and simplifies any potential troubleshooting activity.
Depending on the model, SteelFusion Edge can be shipped or configured in the field with one or more additional multiple-port network interface cards (NICs). There is a selection of both copper and optical 1‑GbE and 10-GbE NICs that fall into one of two categories. The two categories are bypass cards suitable for use as in-path interfaces for WAN optimization or data cards suitable for LAN connectivity.
In the case of LAN connectivity, the data cards might be for any of the following examples:
• iSCSI traffic to and from servers in the branch that are external to SteelFusion Edge.
• Application traffic from clients in the branch connecting to application servers hosted in the SteelFusion Edge hypervisor node.
• Additional LAN connectivity for redundancy purposes (for example, MPIO, SteelFusion Edge HA, and so on).
You cannot change the mode of the NIC from data to in-path or vice versa. For a complete list of available NICs, their part numbers and installation details, see SteelFusion Edge Hardware and Maintenance Guide.
Choosing the correct cables
The LAN and WAN ports on the SteelFusion Edge bypass cards act like host interfaces during normal operation. During fail-to-wire mode, the LAN and WAN ports act as the ends of a crossover cable. Using the correct cable to connect these ports to other network equipment ensures proper operation during fail-to-wire mode and normal operating conditions. This cabling is especially important when you are configuring two SteelFusion Edge appliances in a serial in-path deployment for HA.
We recommend that you do not rely on automatic MDI/MDI-X to automatically sense the cable type. The installation might be successful when the SteelFusion Edge is optimizing traffic, but it might not be successful if the in-path bypass card transitions to fail-to-wire mode.
One way to help ensure that you use the correct cables during an installation is to connect the LAN and WAN interfaces of the bypass card while the SteelFusion Edge is powered off. This configuration proves that the devices on either side of the appliance can communicate correctly without any errors or other problems.
In the most common in-path configuration, a SteelFusion Edge LAN port is connected to a switch and the SteelFusion Edge WAN port is connected to a router. In this configuration, a straight-through Ethernet cable can connect the LAN port to the switch, and you must use a crossover cable to connect the WAN port to the router.
When you configure SteelFusion Edge in HA, it is likely that you have one or more additional data NICs installed into the appliance to provide extra interfaces. You can use the interfaces for MPIO and blockstore synchronization.
This table summarizes the correct cable usage in the SteelFusion Edge when you are connecting LAN and WAN ports or when you are connecting data ports.
Devices | Cable |
SteelFusion Edge to SteelFusion Edge | Crossover |
SteelFusion Edge to router | Crossover |
SteelFusion Edge to switch | Straight-through |
SteelFusion Edge to host | Crossover |
Overview of SteelFusion Edge HA
This section describes HA features, design, and deployment of SteelFusion Edge. You can assign the LUNs provided by SteelFusion Edge (which are projected from the Core in the data center) in a variety of ways. Whether used as a datastore for VMware ESXi in the hypervisor node, or for other hypervisors and discrete servers hosted externally in the branch office, the LUNs are always served from the SteelFusion Edge using the iSCSI protocol.
Because of the way the LUNs are served, you can achieve HA with SteelFusion Edge by using one or both of the following two options:
These options are independent of any HA Core configuration in the data center that is projecting one or more LUNs to the SteelFusion Edge. However, because of different SteelFusion Edge deployment options and configurations, there are several scenarios for HA. For example, you can consider hardware redundancy consisting of multiple power supplies or RAID inside the SteelFusion Edge appliance as a form of HA. For more information about hardware, see the product specification documents.
Alternatively, when you deploy two SteelFusion Edge appliances in the branch, you can configure the VSP on both devices to provide an active-passive capability for any VMs that are hosted on the hypervisor node. In this context, HA is purely from the point of view of the VMs themselves, and there is a separate SteelFusion Edge providing a failover instance of the hypervisor node.
For more details about how to configure SteelFusion Edge HA, see the SteelFusion Edge Management Console User’s Guide.
SteelFusion Edge with MPIO
In a similar way to how you use MPIO with Core and data center storage arrays, you can use SteelFusion Edge with MPIO at the branch. Using SteelFusion Edge with MPIO ensures that a failure of any single component (such as a network interface card, switch, or cable) does not result in a communication problem between SteelFusion Edge and the iSCSI Initiator in the host device at the branch.
Figure: Basic topology for SteelFusion Edge MPIO shows a basic MPIO architecture for SteelFusion Edge. In this example, the primary and eth2_0 interfaces of the SteelFusion Edge are configured as the iSCSI portals, and the server interfaces (NIC-A and NIC-B) are configured as iSCSI Initiators. Combined with the two switches in the storage network, this basic configuration allows for failure of any of the components in the data path while continuing to enable the server to access the iSCSI LUNs presented by the SteelFusion Edge.
Figure: Basic topology for SteelFusion Edge MPIO
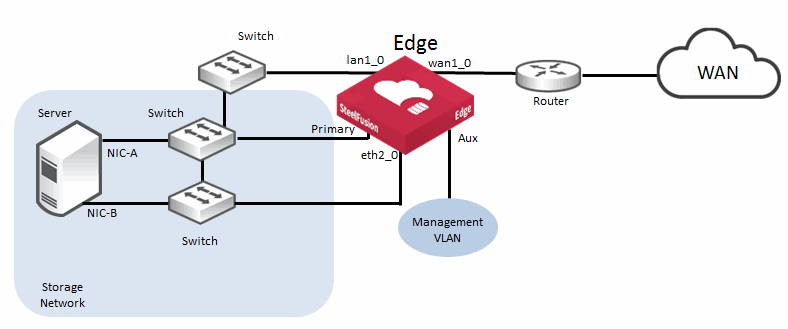
While you can use other interfaces on the SteelFusion Edge as part of an MPIO configuration, we recommend that you use the primary interface and one other interface that you are not using for another purpose. The SteelFusion Edge can have an additional multiport NIC installed to provide extra interfaces. This additional card is especially useful in HA deployments. The eth2_0 interface in this example is provided by an optional add-on four-port NIC that has been installed in slot 2 of the appliance.
For more information about multiport NICs, see
Edge appliances ports.
When using MPIO with SteelFusion Edge, we recommend that you verify and adjust certain timeout variables of the iSCSI Initiator in the server to make sure that you have correct failover behavior.
By default, the Microsoft iSCSI Initiator LinkDownTime timeout value is 15 seconds. This timeout value determines how much time the initiator holds a request before reporting an iSCSI connection error.
If you are using SteelFusion Edge in an HA configuration, and MPIO is configured in the Microsoft iSCSI Initiator of the branch server, change the LinkDownTime timeout value to 60 seconds to allow the failover to finish.
Note: When you view the iSCSI MPIO configuration from the ESXi vSphere management interface, even though both iSCSI portals are configured and available, only iSCSI connections to the active SteelFusion Edge are displayed.
For more details about the specific configuration of MPIO, see the SteelFusion Edge Management Console User’s Guide.
SteelFusion Edge HA using blockstore synchronization
While MPIO can cater to HA requirements involving network redundancy in the branch office, it still relies on the SteelFusion Edge itself being available to serve LUNs. To survive a failure of the SteelFusion Edge without downtime, you must deploy a second appliance. If you configure two appliances as an HA pair, the SteelFusion Edge can continue serving LUNs without disruption to the servers in the branch, even if one of the SteelFusion Edge appliances were to fail. The serving of LUNs in a SteelFusion Edge HA deployment can be used by the VSP of the second SteelFusion Edge and by external servers within the branch office.
The scenario described in this section has two SteelFusion Edges operating in an active-standby role. This scenario is irrespective of whether the Core is configured for HA in the data center.
The active SteelFusion Edge is connected to the Core in the data center and is responding to the read and write requests for the LUNs it is serving in the branch. This method of operation is effectively the same as with a single SteelFusion Edge; however, there are some additional pieces that make up a complete HA deployment.
Note: If you plan to configure two SteelFusion Edge appliances into an HA configuration at a branch, we strongly recommend you do this configuration at the time of installation. Adding a second SteelFusion Edge to form an HA pair at a later date is possible but is likely to result in disruption to the branch services while the reconfiguration is performed.
The standby SteelFusion Edge does not service any of the read and write requests but is ready to take over from the active peer.
As the server writes new data to LUNs through the blockstore of the active SteelFusion Edge, the data is reflected synchronously to the standby peer blockstore. When the standby peer has acknowledged to the active peer that it has written the data to its own blockstore, the active peer then acknowledges the server. In this way, the blockstores of the two SteelFusion Edges are kept in lock step.
Figure: Basic topology for SteelFusion Edge high availability illustrates a basic HA configuration for SteelFusion Edge. While this figure is a very simplistic deployment diagram, it highlights the importance of the best practice to use two dedicated interfaces between the SteelFusion Edge peers to keep their blockstores synchronized. We strongly recommend you configure the SteelFusion Edges to use eth0_0 and eth0_1 as their interfaces for synchronization and failover status. Using dedicated interfaces through crossover cables ensures that a split-brain scenario (in which both peer devices think the other has failed and start serving independently) is minimized.
Figure: Basic topology for SteelFusion Edge high availability
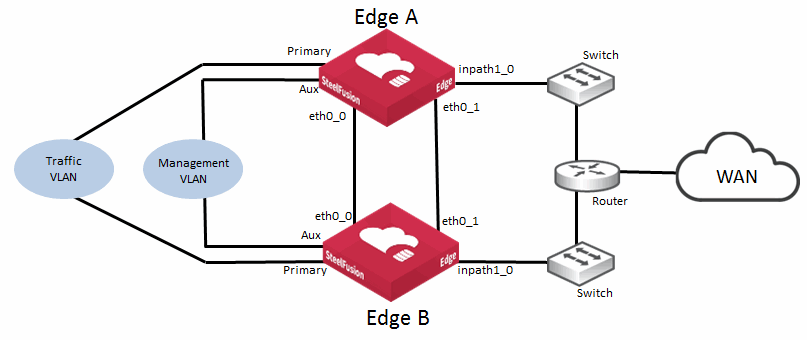
Prior to SteelFusion v4.2 software, although two interfaces are configured, only one interface is actively sending blockstore synchronization traffic. In SteelFusion v4.2 and later, the Edge software includes Multipath NetDisk. With this new feature, you can load balance the blockstore synchronization traffic across both interfaces. Multipath NetDisk continues to provide resiliency for the blockstore synchronization but also delivers higher performance. You do not need to do any additional configuration to enable this capability if both Edges are running SteelFusion v4.2 or later.
If the interfaces used for blockstore synchronization are of different capacities (for example, one is 1 Gbps and the other is 10 Gbps), then we recommend that you specify the higher capacity interface first.
For more configuration details, see the SteelFusion Edge Management Console User’s Guide.
SteelFusion Edge HA peer communication
When you configure two SteelFusion Edges as active-standby peers for HA, they communicate with each other at regular intervals. The communication is required to ensure that the peers have their blockstores synchronized and that they are operating correctly based on their status (active or standby).
The blockstore synchronization happens through two network interfaces that you configure for this purpose on the SteelFusion Edge. Ideally, these are dedicated interfaces, preferably connected through crossover cables. Although not the preferred method, you can send blockstore synchronization traffic through other interfaces that are already being used for another purpose. If interfaces must be shared, then avoid using the same interfaces for both iSCSI traffic and blockstore synchronization traffic. These two types of traffic are likely to be quite intensive. Instead, use an interface that is more lightly loaded: for example, management traffic.
The interfaces used for the actual blockstore synchronization traffic are also used by each peer to check the status of one another through the heartbeat messages. The heartbeat messages provide each peer with the status of the other peer and can include peer configuration details.
A heartbeat message is sent by default every 3 seconds through TCP port 7972. If the peer fails to receive three successive heartbeat messages, then a failover event can be triggered. Because heartbeat messages are sent in both directions between SteelFusion Edge peers, there is a worst-case scenario in which failover can take up to 18 (3 x 3 x 2) seconds.
Failovers can also occur due to administrative intervention: for example, rebooting or powering off a SteelFusion Edge.
The blockstore synchronization traffic is sent between the peers using TCP port 7973. By default, the traffic uses the first of the two interfaces you configure. If the interface is not responding for some reason, the second interface is automatically used.
If neither interface is operational, then the SteelFusion Edge peers enter into some predetermined failover state based on the failure conditions.
The failover state on a SteelFusion Edge peer can be one of the following:
• Discover - Attempting to establish contact with the other peer.
• Active Sync - Actively serving client requests; the standby peer is in sync with the current state of the system.
• Standby Sync - Passively accepting updates from the active peer; in sync with the current state of the system.
• Active Degraded - Actively serving client requests; cannot contact the standby peer.
• Active Rebuild - Actively serving client requests; sending the standby peer updates that were missed during an outage.
• Standby Rebuild - Passively accepting updates from the active peer; not yet in sync with the state of the system.
For detailed information about how to configure two SteelFusion Edges as active-standby failover peers, the various failover states that each peer can assume while in an HA deployment, and the procedure required to remove an active-standby pair from that state, see the SteelFusion Edge Management Console User’s Guide.
Recovering from split-brain scenarios involving Edge appliance HA
Even though the communication between the peers of an Edge HA deployment is designed for maximum resiliency, there is a remote possibility of a failure scenario known as split brain. Split brain can occur if the heartbeat communication between the peers fails simultaneously in all aspects; that is, both heartbeat interfaces fail at the same time. If these interfaces are directly connected through cross-over cables then the possibility is extremely remote. But if the heartbeat interfaces are connected through network switches, then depending on the design and topology, split brain might occur.
In a split-brain condition, both Edge appliances act as if the peer has failed. This action can result in both peers being Active Degraded. Because both peers can be simultaneously trying to serve data and also be synchronizing data back through the Core, this action could lead to data integrity issues.
There are ways to recover from this scenario, but the best course of action to begin with is to contact Riverbed Support and open a support case. Any recovery process is likely to be different from another so the actual procedure may vary depending on the failure sequence.
Note: The recovery process can involve accessing a previous snapshot of the affected LUNs.
Testing HA failover deployments
There are many ways that you can test a failover configuration of Core HA or Edge HA. These tests may include power-cycling, SteelFusion HA peer device reboot, or any number of network connection failure scenarios (routers, switches, cables).
Your failover test should at least satisfy the basic requirements that ensure the SteelFusion HA deployment recovers as expected.
The simplest test is to perform an orderly reboot of a SteelFusion peer device (Core or Edge) that is one half of an HA configuration.
Configuring WAN redundancy
This section describes how to configure WAN redundancy. It includes the following topics:
You can configure the Core and Edge with multiple interfaces to use with MPIO. You can consider this configuration a form of local network redundancy. Similarly, you can configure multiple interfaces to provide a degree of redundancy across the WAN between the Core and the Edge. This redundancy ensures that any failure along the WAN path can be tolerated by the Core and the Edge, and is called WAN redundancy.
WAN redundancy provides multiple paths for connection in case the main Core to Edge link fails.
To configure WAN redundancy, you perform a series of steps on both the data center and branch side.
You can use both the in-path interfaces (inpathX_Y) or Ethernet interfaces (ethX_Y) for redundant WAN link configuration. In the examples below the term intf is used to imply either in-path or Ethernet network interfaces.
Configuring WAN redundancy with no Core HA
This section describes how to configure WAN redundancy when you do not have a Core HA deployment.
To configure WAN redundancy
1. Configure local interfaces on the Edge. The interfaces are used to connect to the Core:
• From the Edge Management Console, choose Storage > Storage Edge Configuration.
• Click Add Interface.
Figure: Edge
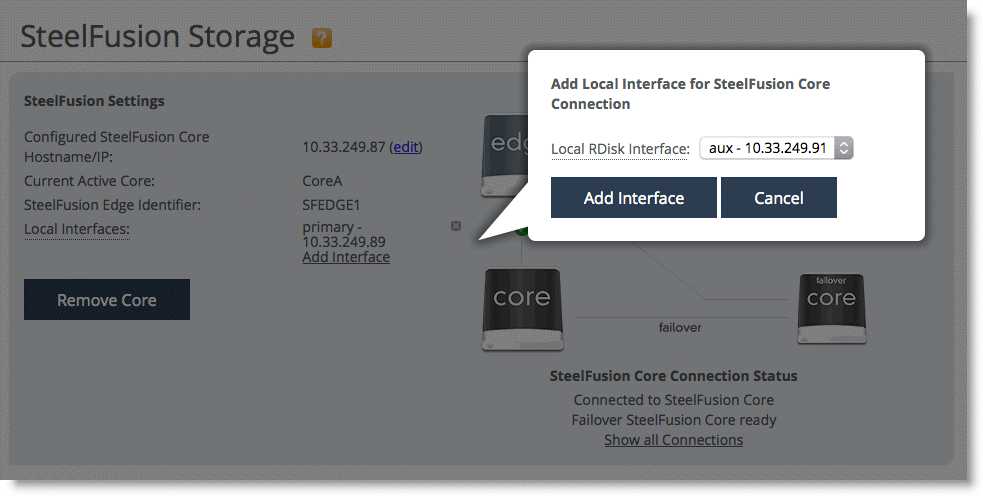
interfaces
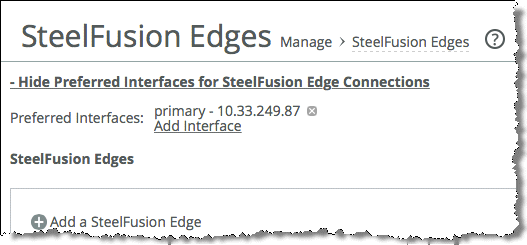
2. Configure preferred interfaces for connecting to the Edge on the Core:
• From the Core Management Console, choose Configure > Manage: SteelFusion Edges.
• Select Show Preferred Interfaces for SteelFusion Edge Connections.
• Click Add Interface.
Figure: Adding Core interfaces
On first connection, the Core sends all the preferred interface information to the Edge. The Edge uses this information along with configured local interfaces to connect on each link (local-interface and preferred-interface pair) until a successful connection is formed. The Edge tries each connection three times (and waits 3 seconds before the next try) before it moves on to the next; that is, if the first link fails, the next link is tried in nine seconds.
After the Core and the Edge have established a successful alternative link, the Edge updates its Rdisk configuration with the change, so that the configuration is on the same link as the management channel between Core and Edge.
3. Remove the local interface for WAN redundancy on Edge:
• From the Edge Management Console, choose Storage > Storage Edge Configuration.
• Open the interface you want to remove.
• Click Remove Interface.
4. Remove preferred interfaces for WAN redundancy on the Core:
• From the Core Management Console, choose Configure > Manage: SteelFusion Edges.
• Select Show Preferred Interfaces for SteelFusion Edge Connections.
• Open the interface you want to remove.
• Delete the interface.
Any change in the preferred interfaces on the Core is communicated to the Edge and the connection is updated as needed.
Configuring WAN redundancy in an HA environment
In an Core HA environment, the preferred interfaces information of the failover Core is sent to the Edge by the primary Core. The connection between the Edge and the failover Core follows the same logic in which a connection is tried on each link (local interface and preferred interface pair) until a connection is formed.
Related information
• SteelFusion Core Management Console User’s Guide
• SteelFusion Edge Management Console User’s Guide
• SteelFusion Core Installation and Configuration Guide
• SteelFusion Command-Line Interface Reference Manual
• Riverbed Splash at https://splash.riverbed.com/community/product-lines/steelfusion