In-Path Redundancy and Clustering Examples
You can use the following techniques to configure multiple SteelHeads in physical in-path deployments. These deployments achieve redundancy and clustering for optimization. This section covers the following scenarios:
Primary and Backup DeploymentsSerial Cluster DeploymentsYou can use the techniques in each scenario to provide optimization across several physical links. You can use these techniques in conjunction with connection forwarding when all of the physical links to and from the WAN are unable to pass through a single SteelHead.
For information about connection forwarding, see
Connection Forwarding.
Primary and Backup Deployments
In a primary and backup deployment, two equivalent model SteelHeads are placed physically in-path. This section includes the following topics:
Configuring a Primary and Backup DeploymentAdjusting the Timers for Faster Primary and Backup FailoverThe SteelHead closest to the LAN is configured as a primary, and the other SteelHead as the backup. The primary SteelHead optimizes traffic and the backup SteelHead checks to make sure the primary SteelHead is functioning and not in admission control. Admission control means the SteelHead has stopped trying to optimize new connections, due to reaching its TCP connection limit, or due to some abnormal condition. If the backup SteelHead cannot reach the primary, or if the primary has entered admission control, the backup SteelHead begins optimizing new connections until the primary recovers. After the primary has recovered, the backup SteelHead stops optimizing new connections, but continues to optimize any existing connections that were made while the primary was down. The recovered primary optimizes any newly formed connections.
Figure 9‑7. Primary and Backup Deployment

If you use the primary and backup deployment method with SteelHeads that have multiple active in-path links, peering rules must also be configured. Add peering rules to both SteelHeads for each in-path interface; these peering rules must have an action pass for a peer IP address of each of the in-path IP addresses. This setting ensures that during any window of time during which both SteelHeads are active (for example, during a primary recovery), the SteelHeads do not try to optimize connections between themselves.
Typically, RiOS data store synchronization is used in primary and backup deployments. RiOS data store synchronization ensures that any data written to one SteelHead eventually is pushed to the other SteelHead. Although both the primary and backup deployment option and the RiOS data store synchronization feature use the terms primary and backup, the uses are different and separate. You can typically configure one SteelHead to be a primary for both, but it is not a requirement.
For information about data synchronization, see
RiOS Data Store Synchronization.
Consider using a primary and backup deployment instead of a serial cluster when all of the following are true:
Only two SteelHeads are placed physically in-path.The capacity of a single SteelHead is sufficient for the site.Only a single in-path interface is active on both SteelHeads.Some environments might require additional considerations. For more information, see the Riverbed Support site at
https://support.riverbed.com.
Configuring a Primary and Backup Deployment
This section describes how to configure the primary and backup deployment shown in
Figure 9‑7.
To configure the primary and backup SteelHeads
Connect to the primary SteelHead CLI and enter the following commands:
interface primary ip address 10.0.1.2/24
ip default gateway 10.0.1.1
interface inpath0_0 ip address 10.0.1.3/24
ip in-path-gateway inpath0_0 10.0.1.1
failover steelhead addr 10.0.1.5
failover master
failover enable
in-path enable
datastore sync master
datastore sync peer-ip 10.0.1.4
datastore sync enable
write memory
restart
Connect to the backup SteelHead CLI and enter the following commands:
interface primary ip address 10.0.1.4/24
ip default gateway 10.0.1.1
interface inpath0_0 ip address 10.0.1.5/24
ip in-path-gateway inpath0_0 10.0.1.1
failover steelhead addr 10.0.1.3
no failover master
failover enable
in-path enable
no datastore sync master
datastore sync peer-ip 10.0.1.2
datastore sync enable
write memory
restart
For more information about configuring primary and backup deployment, see the Failover Support commands in the Riverbed Command-Line Interface Reference Manual, and the Enabling Failover section in the SteelHead Management Console User’s Guide.
Adjusting the Timers for Faster Primary and Backup Failover
In a steady, normal operating state, the backup SteelHead periodically sends keep-alive messages to the primary SteelHead on TCP port 7820. If the primary SteelHead does not respond to the keep-alive message within 5 seconds, the backup SteelHead drops the connection and attempts to reconnect to the primary SteelHead. The backup SteelHead attempts to reconnect a maximum of five times, and each time it waits for 2 seconds before aborting the connection.
If all connection attempts fail, the backup SteelHead transitions into an active state and starts optimizing the connections. If you use the default value failover settings, it can take as long as 15 seconds before the backup SteelHead starts optimizing connections.
You can adjust several failover settings to shorten the failover time:
Read timeout (in milliseconds) - Governs how many milliseconds the backup SteelHead waits for the primary SteelHead to respond to its keep-alive messages. Use the failover read timeout command to adjust this setting. The default value is 5000 ms. Connection attempts - The number of times the backup SteelHead attempts to reconnect to the primary SteelHead after read time-out has expired. Use the failover connection attempts command to adjust this setting. The default value is 5.Connection timeout (in milliseconds) - The number of milliseconds the backup SteelHead waits before aborting the reconnection attempt to the primary SteelHead. Use the failover connection timeout command to adjust this setting. The default value is 2000 ms.To reduce the failover time to five seconds, you can adjust the timers to the following:
Read timeout - 1000 msConnection attempts - 4Connection timeout - 1000 msSerial Cluster Deployments
You can provide increased optimization by deploying two or more SteelHeads back-to-back in an in-path configuration to create a serial cluster. This section includes the following topics:
Serial Cluster RulesConfiguring a Basic Serial Cluster DeploymentConfiguring Faster Peer Failure DetectionSteelHeads in a serial cluster process the peering rules you specify in a spillover fashion. When the maximum number of TCP connections for a SteelHead is reached, that appliance stops intercepting new connections. This allows the next SteelHead in the cluster the opportunity to intercept the new connection, if it has not reached its maximum number of connections.
The in-path peering rules and in-path rules tell the SteelHead in a cluster not to intercept connections between themselves. You configure peering rules that define what to do when a SteelHead receives an auto-discovery probe from another SteelHead. You can deploy serial clusters on the client or server-side of the network.
For environments in which you want to optimize MAPI or FTP traffic, which require all connections from a client to be optimized by one SteelHead, Riverbed strongly recommends using the primary and backup redundancy configuration instead of a serial cluster deployment. For larger environments that require multiple appliance scalability and high availability, Riverbed recommends using the SteelHead Interceptor to build multiple appliance clusters. For details, see the SteelHead Interceptor User’s Guide.
Before you configure a serial cluster deployment, consider the following factors:
The total optimized WAN capacity of the cluster can reach the sum of the optimized WAN capacity of the individual SteelHeads, assuming that both SteelHeads are optimizing connections. Typically, both SteelHeads optimize connections if connections originate from both WAN and LAN, or if one of the SteelHeads reaches its capacity limit and passes through subsequent connections (which are then optimized by the other SteelHead).If the active SteelHead in the cluster enters a degraded state because the CPU load is too high, it continues to accept new connections.For more information about working with serial clusters, see the Riverbed Knowledge Base article
Working with Serial Clustering at
https://supportkb.riverbed.com/support/index?page=content&id=s15555. Serial Cluster Rules
The in-path peering rules and in-path pass-through rules tell the SteelHeads in a serial cluster not to intercept connections between each other. The peering rules define what happens when a SteelHead receives an auto-discovery probe from another SteelHead in the same cluster.
You can deploy serial clusters on the client or server side of the network.
Figure 9‑8. Serial Cluster Deployment
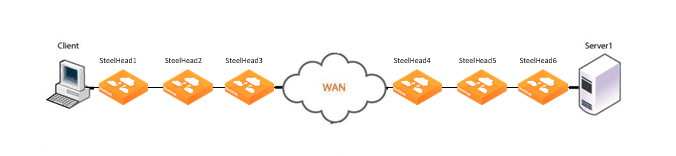
In this example, SteelHead 1, SteelHead 2, and SteelHead 3 are configured with in-path peering rules so they do not answer probe requests from one another, and with in-path rules so they do not accept their own WAN connections. Similarly, SteelHead 4, SteelHead 5, and SteelHead 6 are configured so that they do not answer probes from one another and do not intercept inner connections from one another. The SteelHeads are configured to find an available peer SteelHead on the other side of the WAN.
Configuring a Basic Serial Cluster Deployment
Figure 9‑9 shows an example serial cluster deployment of three in-path SteelHeads in a data center.
Figure 9‑9. Serial Cluster in a Data Center

This example uses the following parameters:
SteelHead 1 in-path IP address is 10.0.1.1 SteelHead 2 in-path IP address is 10.0.1.2 SteelHead 3 in-path IP address is 10.0.1.3 In this example, you configure each SteelHead with in-path peering rules to prevent peering with another SteelHead in the cluster, and with in-path rules to not optimize connections originating from other SteelHeads in the same cluster.
To configure a basic serial cluster deployment with three SteelHeads
On SteelHead 1, connect to the CLI and enter the following commands:
enable
configure terminal
in-path peering rule pass peer 10.0.1.2 rulenum 1
in-path peering rule pass peer 10.0.1.3 rulenum 1
in-path rule pass-through srcaddr 10.0.1.2/32 rulenum 1
in-path rule pass-through srcaddr 10.0.1.3/32 rulenum 1
write memory
show in-path peering rules
Rule Type Source Network Dest Network Port Peer Addr
----- ------ ------------------ ------------------ ----- ---------------
1 pass * * * 10.0.1.3
2 pass * * * 10.0.1.2
def auto * * * *
show in-path rules
Rule Type Source Addr Dest Addr Port Target Addr Port
----- ---- ------------------ ------------------ ----- --------------- -----
1 pass 10.0.1.3/24 * * -- --
2 pass 10.0.1.2/24 * * -- --
def auto * * * -- --
The changes take effect immediately. You must save your changes or they are lost upon reboot.
On SteelHead 2, connect to the CLI and enter the following commands:
enable
configure terminal
in-path peering rule pass peer 10.0.1.1 rulenum 1
in-path peering rule pass peer 10.0.1.3 rulenum 1
in-path rule pass-through srcaddr 10.0.1.1/32 rulenum 1
in-path rule pass-through srcaddr 10.0.1.3/32 rulenum 1
write memory
show in-path peering rules
Rule Type Source Network Dest Network Port Peer Addr
----- ------ ------------------ ------------------ ----- ---------------
1 pass * * * 10.0.1.3
2 pass * * * 10.0.1.1
def auto * * * *
show in-path rules
Rule Type Source Addr Dest Addr Port Target Addr Port
----- ---- ------------------ ------------------ ----- --------------- -----
1 pass 10.0.1.3/24 * * -- --
2 pass 10.0.1.1/24 * * -- --
def auto * * * -- --
The changes take effect immediately. You must save your changes or they are lost upon reboot.
On SteelHead 3, connect to the CLI and enter the following commands:
enable
configure terminal
in-path peering rule pass peer 10.0.1.1 rulenum 1
in-path peering rule pass peer 10.0.1.2 rulenum 1
in-path rule pass-through srcaddr 10.0.1.1/32 rulenum 1
in-path rule pass-through srcaddr 10.0.1.2/32 rulenum 1
write memory
show in-path peering rules
Rule Type Source Network Dest Network Port Peer Addr
----- ------ ------------------ ------------------ ----- ---------------
1 pass * * * 10.0.1.2
2 pass * * * 10.0.1.1
def auto * * * *
show in-path rules
Rule Type Source Addr Dest Addr Port Target Addr Port
----- ---- ------------------ ------------------ ----- --------------- -----
1 pass 10.0.1.2/24 * * -- --
2 pass 10.0.1.1/24 * * -- --
def auto * * * -- --
The changes take effect immediately. You must save your changes or they are lost upon reboot.
Port 7800 is the default pass-through port. The SteelHeads by default passes through and not intercept SYN packets arriving on port 7800. These in-path pass-through rules are necessary only if the SteelHeads have been configured to use service ports other than 7800 for the SteelHead-to-SteelHead connections.
Configuring Faster Peer Failure Detection
A SteelHead uses the out-of-band (OOB) connection to inform a peer SteelHead of its capabilities. The OOB connection is also used to detect failures. By default, a SteelHead sends a keep-alive message every 20 seconds, and it declares a peer down after sending two keep-alive messages (40 seconds) and no response is received. If you want faster peer failure detection, use the following commands to adjust the interval and the number of keep-alive messages sent:
protocol connection wan keep-alive oob def-count (default of 2; minimum value of 2)
protocol connection wan keep-alive oob def-intvl (default of 20; minimum value of 5)
Losing the OOB connection does not affect the optimized sessions, because the optimized sessions have a one-to-one mapping between the outer channel (the LAN-side TCP connection between the client and server, and the SteelHead) and the inner channel (the WAN-side TCP connection between the SteelHeads). The disadvantage to this approach is that the application does not notice when the peer is unavailable and the application might appear as if it is not working to the end user.
To address this, you can disconnect the inner and outer channels when the SteelHead loses its OOB connection by using the protocol connection lan on-oob-timeout drop all enable command.
For SteelHeads with multiple in-path interfaces, the protocol connection lan on-oob-timeout drop all enable command disconnects all the optimized sessions, even if there are other OOB connections originating from other in-path interfaces. To configure the SteelHead to drop only the connections related to a specific in-path interface, use the command protocol connection lan on-oob-timeout drop same-inpath enable.
For more information about OOB, see
The Out-of-Band Connection.