Determining Which Metrics to Use
When you configure service monitoring within the NetProfiler, Step 4 of the configuration wizard enables you to decide which metrics to monitor for each segment within the service. The metrics are organized according to three different categories. The following table summarizes all metrics.
Category | Metric Name | Enabled | Dips | Spikes |
Connectivity (Conn) | New connections | | | Yes |
Active connections | Yes | | |
Bandwidth | | Yes | |
User experience (UserExp) | Response time | Yes | | Yes |
Average connection duration | | | Yes |
Average application throughput per connection | | Yes | |
Efficiency (Effncy) | TCP retransmissions | Yes | | Yes |
Number of TCP resets | Yes | | Yes |
The following metrics are enabled by default:
• Active connection rate (detecting spikes)
• Response time (detecting spikes)
• TCP resets (detecting spikes)
• TCP retransmissions (detecting spikes)
When you consider which metrics to use for an application, take into account what each segment is responsive for versus the service as a whole. Front-end segments might have very different characteristics than back-end segments.
For example, if you have a web-connected front end, you might detect numerous brief connections versus a back-end segment for the same service, which might have only continuous database interactions over only a handful of connections. For another service, you might have a front-end segment that uses Citrix, which might keep connections open throughout very long periods of time, while back-end connections to application servers might be shorter in duration but greater in number. For details about characteristics to consider per metric, see
Reducing the Number of Metrics.
The four default, enabled metrics satisfy a majority of TCP-based application segments, although for segments with a low number of connections, you might want to disable or change the settings on the active connections metric.
When you choose which metrics to include, use the following best practice guidelines:
• Applications with low connectivity rates - For back-end segments for which applications have connectivity between only a few servers, or front-end segments for which only a few clients are connected at a time, the active connection rate is very low, and the tolerance band might be very tight. You might detect alerts when there is a very minor change in connectivity (one new session connects longer than what is normal).
For these situations, you can disable this metric, or you can increase the tolerance band and add an appropriate noise floor to the metric. The noise floor can help control minor fluctuations.
Figure: Metric for a Low Connectivity Rate Segment shows a segment that has only a few connections active per second, with a raised tolerance to 5 for low and 6 for high, and an added noise floor of four connections per second.
Figure: Metric for a Low Connectivity Rate Segment
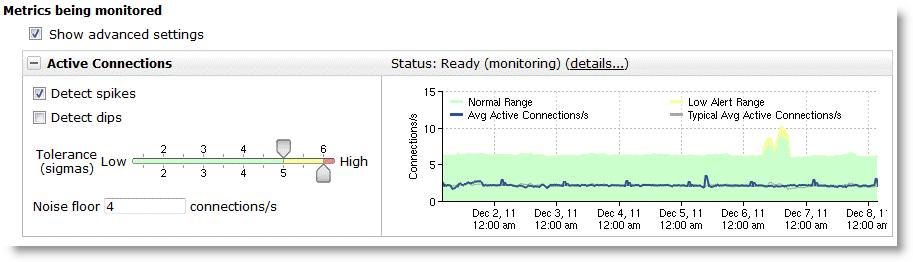
• Active connection rate metric consideration without weekly seasonality - If you are trying to keep the number of alerts low, Riverbed recommends that you not disable the active connections metric until after the weekly baseline is set. The baseline is three weeks and one day of data.
• UDP applications - For UDP applications, the TCP health and TCP performance measurement-based metrics do not work. You can disable TCP resets, TCP retransmissions, and response time. For UDP segments that have periodic bandwidth, you can enable the bandwidth metric.
• Back-end segments with continuous communications - For many back-end segments, you can enable the average application throughput per connection metric. This metric tracks the bandwidth that is consumed during the active parts of the session. You are alerted when the baselined value dips below the threshold. This dip can indicate that less data is transferred, which can indicate that the application efficiency has dropped, and this can have an impact on user experience.
• Single-transaction-oriented TCP sessions - For application segments that tend to set up a new TCP session for each transaction, you can enable the average connection duration metric. This metric tracks the duration of the connections and alerts you if it dips below that baseline. For this type of segment, tracking new connections in addition to active connections can also be beneficial.
• Revisit metrics and tuning after three weeks of data - Although three days and one hour of data are required for the analytic metrics to initialize, it takes three weeks and one day for the analytics to begin using a weekly baseline. This baseline becomes more predictable when you monitor weekly seasonality is monitored (for example, lower traffic volumes on the weekend). Tuning and final decisions on which metrics might not be best for the segment are made after this time period.
• Understanding the characteristics of your application - To better understand the characteristics of the segments on your application, you can run service-level-objective (SLO) reports after the segments have initialized. The SLO reports enable you to see the baselined periodicity of each metric. If the segment has not yet initialized, you can run reports to gain a better understanding of the segment characteristics. Running reports in this manner helps you to choose which metrics to use per segment and to fine-tune after initialization.