SteelFusion Replication (FusionSync)
This chapter describes FusionSync, a replication-based technology between Cores that enables the seamless branch continuity between two data centers. It includes the following topics:
As of the publication of this document, your Cores and SteelFusion Edges must run SteelFusion 4.0 or later.
Note: FusionSync is accessible through the Core Management Console through the Replication menu and through the coredr set of commands using the CLI. References to replication refer to the FusionSync feature.
For more information about SteelFusion Replication, see SteelFusion Core Management Console User’s Guide.
Overview of SteelFusion replication
A single data center is susceptible to large-scale failures (power loss, natural disasters, hardware failures) that can bring down your network infrastructure. To mitigate such scenarios, SteelFusion Replication enables you to connect branch offices to data centers across geographic boundaries and replicate data between them.
In a SteelFusion setup, a typical storage area network (SAN) replication does not protect you from data loss in case of a data center failure, nor from network downtime that can affect many branch offices at the same time. FusionSync enables Cores in two geographically dispersed data centers to remain in synchronization and enables the Edges to switch to another Core in case of disaster. FusionSync can prevent data loss and downtime.
Architecture of SteelFusion replication
This section describes the architecture of SteelFusion Replication. It contains the following topics:
SteelFusion replication components
SteelFusion Replication includes the following components:
• Primary Core - A role of Core that actively serves the LUNs to the Edges and replicates new writes to a secondary Core. During normal operations, the primary Core is located at the preferred data center. When a disaster, a failure, or maintenance affects the preferred data center, the primary Core fails over to the secondary Core at the disaster recovery site. After the failover, the secondary Core becomes primary.
• Secondary Core - A role of Core that receives replicated data from the primary Core. The secondary Core does not serve the storage LUNs to the Edges. On failover, the secondary Core changes its role to primary Core.
• Replication pair - A term used to describe the primary and secondary Core located in separate data centers and configured for FusionSync.
• Replica LUNs - LUNs at the secondary data center that are mapped to the secondary Core and kept in sync with the primary Core LUNs in the primary data center by using FusionSync.
• Journal LUN - A dedicated LUN that is mapped to the Cores from the local backend storage array. Each Core has its own Journal LUN. When FusionSync replication is suspended, the Core uses the Journal LUN to log the write operations from Edges.
• Witness - A role assigned to one of the Edges. A Witness registers requests to suspend replication from the Cores. A Witness makes sure that only one Core at a time suspends its replication. This suspended replication prevents a split-brain scenario and ensures the Edge’s write operations are logged to the Journal LUN on the Core approved by the witness.
You must meet the following requirements to set up replication:
• You must configure the backend storage array for each Core that is included in the replication configuration.
• The primary data center can reach the secondary data center through the chosen interfaces.
• The secondary Core cannot have any active Edges or LUNs.
• Each replica LUN must be the same size (within 1 GiB) because its LUN counterpart is in the primary data center.
• The secondary Core must be either the same or larger specification model as the primary Core.
• If you have HA configured on the primary Cores of the data center, you must also configure it on the secondary Cores. The HA configuration must be the same in each case.
• The Edges can reach the secondary data center.
SteelFusion replication design overview
This section describes the communication and general data flow between Cores that are deployed as part of a SteelFusion Replication (FusionSync) design.
In a deployment in which there is just a single data center and a Core without FusionSync, the Edge acknowledges the write operations to local hosts in the branch, temporarily saves the data in its blockstore marking it as uncommitted, and then asynchronously sends the write operations to the Core. The Core writes the data to the LUN in the data center storage array. After the Core has received an acknowledgment from the storage array, the Core then acknowledges the Edge. The Edge can then mark the relevant blockstore contents as committed. In this way, the Edge is always maintaining data consistency.
To maintain data consistency between the Edge and the two data centers—with a Core in each data center and FusionSync configured—the data flow is somewhat different.
In the steady state, the Edge acknowledges the write operations to local hosts, temporarily saves the data in its blockstore marking it as uncommitted, and asynchronously sends the write operations to its Core. When you configure FusionSync, the primary Core applies the write operations to backend storage and replicates the write operations to secondary Core. The data is replicated between the Cores synchronously, meaning that a write operation is acknowledged by the primary Core to the Edge only when both the local storage array and the secondary Core, along with its storage array, have acknowledged the data.
The Edge marks the relevant blockstore content as committed only when the primary Core has finally acknowledged the Edge.
If the primary Core loses its connection to the secondary Core, it pauses FusionSync. When FusionSync is paused, writes from the Edge to the Core are not acknowledged by the Core. The Edge continues to acknowledge the local hosts in the branch and buffer the writes similar to its behavior when the WAN connectivity to Core goes down, without FusionSync. Although write operations between Edge and Core are not available, read operations are not affected, and read requests from the Edges continue to be serviced by the same Core as normal.
When the connectivity comes back up, FusionSync continues automatically. If, for any reason, the connectivity between the Cores takes a long time to recover, the uncommitted data in the Edges might continue to increase. Uncommitted data in the Edge can lead to a full blockstore. If the blockstore write reserve is in danger of reaching capacity, you can suspend FusionSync. When FusionSync is suspended, the primary Core accepts writes from the Edges, keeps a log of the write operations on its Journal LUN and acknowledges the write operations to the Edges so that the blockstore data is marked as committed.
When a primary Core is down, a secondary Core can take over the primary role. You have to manually initiate the failover on the secondary Core. The Edges maintain connectivity to both Cores (primary and secondary) when the failover occurs, the surviving Core automatically contacts the Edges to move all Edge data connections to the secondary Core. At this point, the secondary Core becomes primary with its Replication suspended. Now the new primary Core acknowledges writes from Edges, applies them to the storage array, logs the operations into the Journal LUN, and acknowledges the write operations to the Edges. When the connectivity between the Cores is restored, the new primary Core starts resynchronizing writes logged in the Journal LUN through the Core in the original data center (the old primary Core) to the LUNs. In this recovery scenario, the old primary Core now becomes the secondary Core and all the LUNs protected by FusionSync are brought back into the synchronization with their replicas.
Whatever the failover scenario, when the failed data center and Core are brought back online and connectivity between data centers is restored, you can failback to the original data center by initiating a failover at the active (secondary) data center. Because a failover is only possible if the primary Core is not reachable by the secondary Core and the Witness, you must manually bring down the primary Core. You can accomplish this process by stopping the Core service on the current primary Core (in the secondary data center) and then initiating a failover on the old primary Core located in the primary data center.
As with any high-availability scenario, there may be a possibility of a split-brain condition. In the case of SteelFusion Replication, it is when both the primary and secondary Cores are up and visible to Edges but cannot communicate to each other. FusionSync could become suspended on both sides and the Edges send writes to both Cores, or some writes to the Core and some to the other. Writing to both sides leads to a condition when both Cores are journaling and neither Core has a consistent copy of the data. More than likely, split brain results in a data loss. To prevent the issue, you must define one of the Edges as a Witness.
The Witness must approve the request that comes to the Cores to suspend replication. The Witness makes sure that both primary and secondary Cores do not get approval for suspension at the same time. When the request is approved, the Core can start logging the writes to the Journal LUN.
Figure: Replication design overview shows the general design of the FusionSync feature.
Figure: Replication design overview
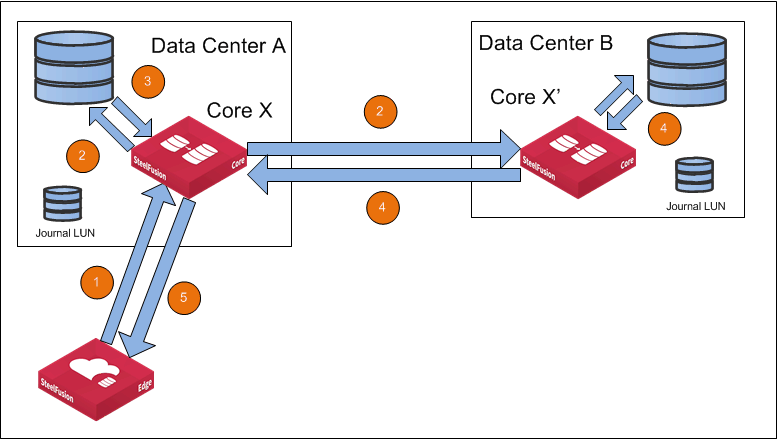
1. A write operation is asynchronously propagated from the Edge to the primary Core (Core X).
2. The Core applies the write operation to the LUN in the backend storage and synchronously replicates the write to the secondary Core (Core X’).
3. The backend storage in Data Center A acknowledges the write to Core X.
4. The secondary Core (Core X’) applies the write to the replica LUN in its backend storage. The storage in Data Center B acknowledges the write to Core X’. Core X’ then acknowledges the write.
5. Core X acknowledges the write to Edge.
Failover scenarios
This section describes the following failover scenarios:
Secondary site is down
Figure: Secondary site is down shows the traffic flow if the secondary site goes down and FusionSync is paused but not suspended.
Figure: Secondary site is down
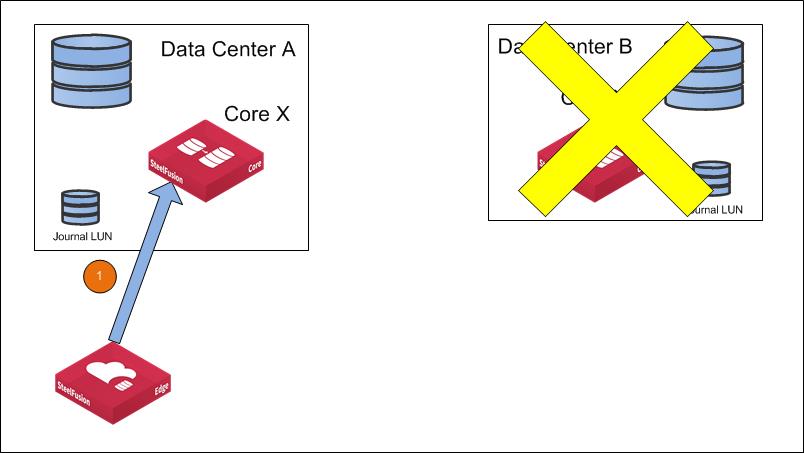
A write from Edges is not acknowledged by the primary Core. The Edges start to buffer the writes locally. Read operations from the Core and read and write operations in the branch office between the Edge and hosts are being performed as usual.
Replication is suspended at the secondary site
Figure: Replication Is suspended at the secondary site shows the traffic flow if FusionSync is suspended at the secondary site.
Figure: Replication Is suspended at the secondary site
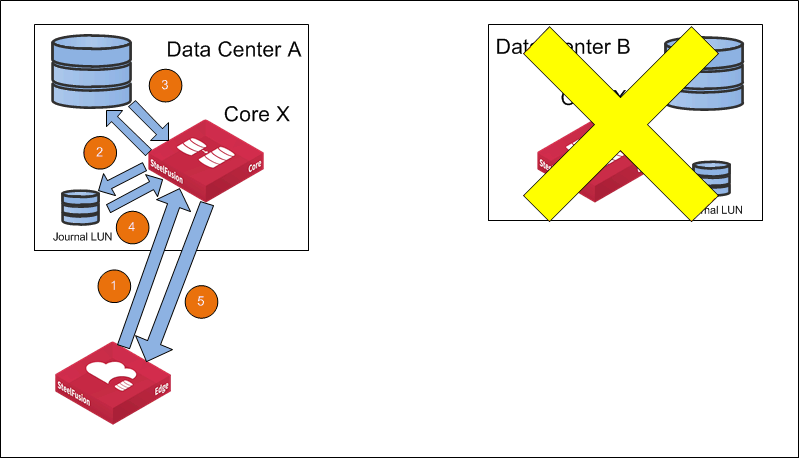
1. A write operation is asynchronously propagated to the primary Core (Core X) from the Edge.
2. The Core applies the write operation to backend storage and logs the write to Journal LUN.
3. The backend storage acknowledges the write.
4. Wait for the write to be journaled.
5. The Core acknowledges the write to the Edge.
Primary site is down (suspended)
Figure: Primary site Is down shows the traffic flow if the primary site (Data Center A) is down and the failover is initiated. The secondary Core assumes the primary role and the connected Edges failover to the secondary site (Data Center B).
Figure: Primary site Is down
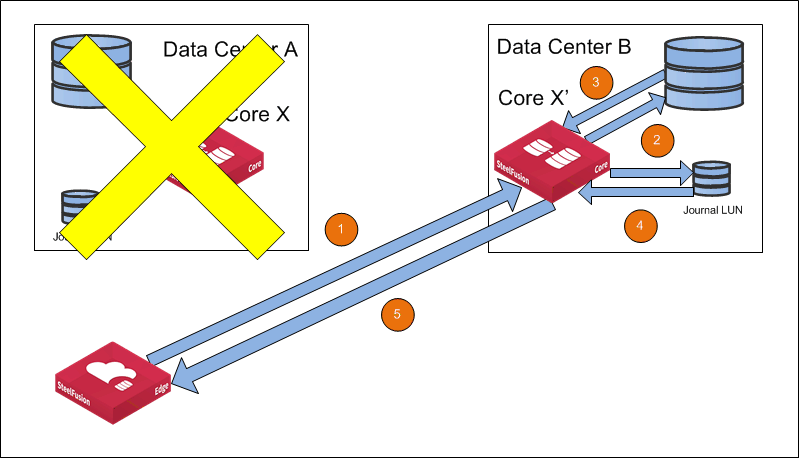
1. A write operation is asynchronously propagated from the Edge to the secondary Core (Core X’) that has assumed the primary role.
2. The Core applies the write operation to backend storage and logs the write to the Journal LUN.
3. The backend storage acknowledges the write.
4. Wait for the write to be journaled.
5. The Core acknowledges the write to the Edge.
FusionSync high-availability considerations
This section describes design considerations when FusionSync is implemented in conjunction with high availability (HA). It contains the following topics:
FusionSync and Core HA
We strongly recommend that you set up your Cores for HA. High-availability deployment provides for redundancy at the Core level within a single data center but not across data centers. Consider FusionSync as an enhancement to HA to protect against data center failures. Do not consider FusionSync as a replacement for HA within the data center. Core HA is active-active by design with each Core separately serving different sets of LUNs to their Edges. Therefore, each Core needs FusionSync configured for those LUNs to their replication peers.
Note: When you have configured Core HA, one Core has the role of the leader and the other has the role of the follower.
Consider the following factors when configuring replication for Cores set up for HA:
• Some configuration changes are only possible on the leader Core. For example, suspend and failover operations are only allowed on the leader. If the leader is down, the follower Core assumes the role of leader.
• You need to configure the same Journal LUN on both the leader and the follower Cores.
• If the primary Core is set up for HA, the secondary Core must be configured for HA too.
• HA must be set up before configuring replication.
• Cores configured for HA must have the same replication role and data center name.
• After you have configured replication, you cannot clear the Core HA.
• When setting up the replication pair, both primary Cores in HA configuration need to be paired to their peers in the secondary data center. For example, Core X paired with Core X' and Core Y is paired with Y'.
• Terminating replication from the primary Core that is set up for HA terminates FusionSync for all four nodes.
Replication HA failover scenarios
This section describes SteelFusion Core HA failover scenarios, with FusionSync.
Figure: HA replication in normal state shows the Core configured for HA at Data Center A that is replicating to Data Center B. Both nodes of the active-active HA cluster are operational and replicating different LUNs to their peers.
Figure: HA replication in normal state
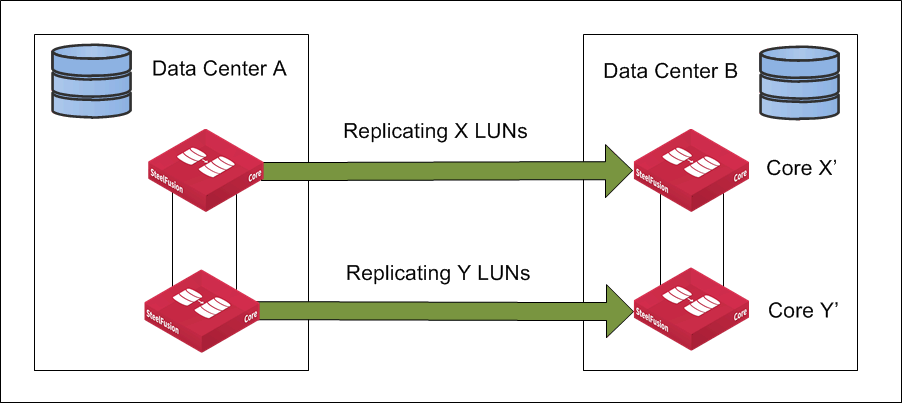
Figure: Core HA Failover on primary data center shows how HA failover at Data Center A is affecting replication. Core Y has failed and Core X took over responsibility for servicing Core Y LUN(s) to Edges, and Core X is replicating the LUN(s) to Core Y' at the same time as continuing to replicate to Core X’ for its own LUNs.
Figure: Core HA Failover on primary data center
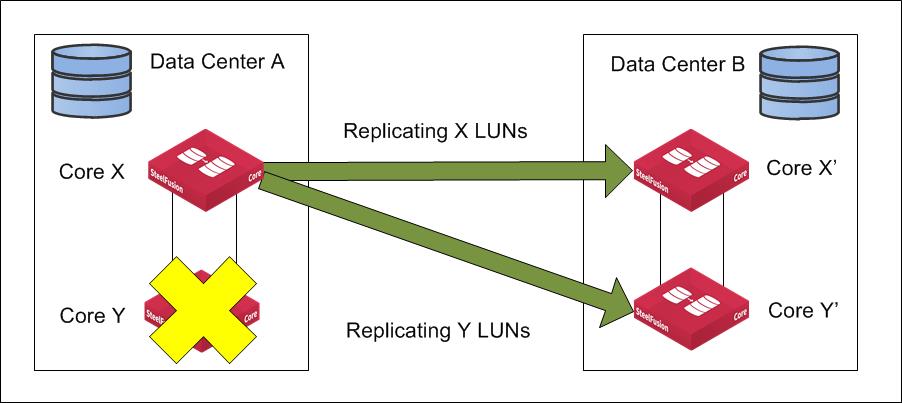
Figure: Core HA failover on secondary data center shows how HA failover at Data Center B is affecting replication. Core Y’ has failed and Core X’ takes over responsibility of the replication target and accepting replication from Core Y and continuing to accept replication traffic from Core X.
Figure: Core HA failover on secondary data center
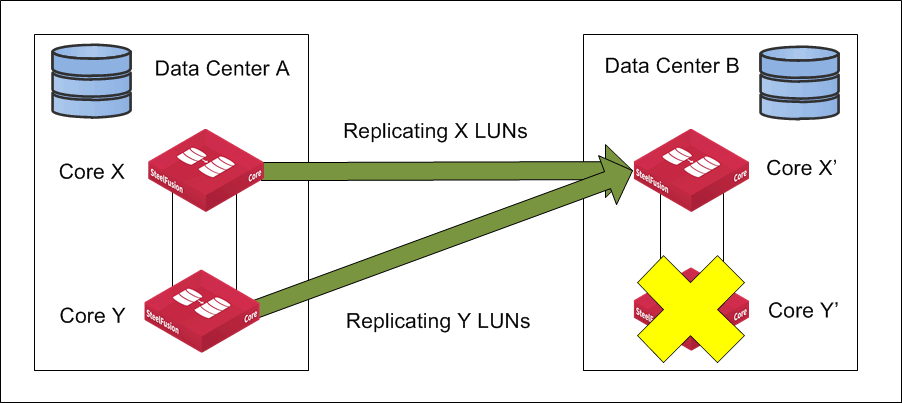
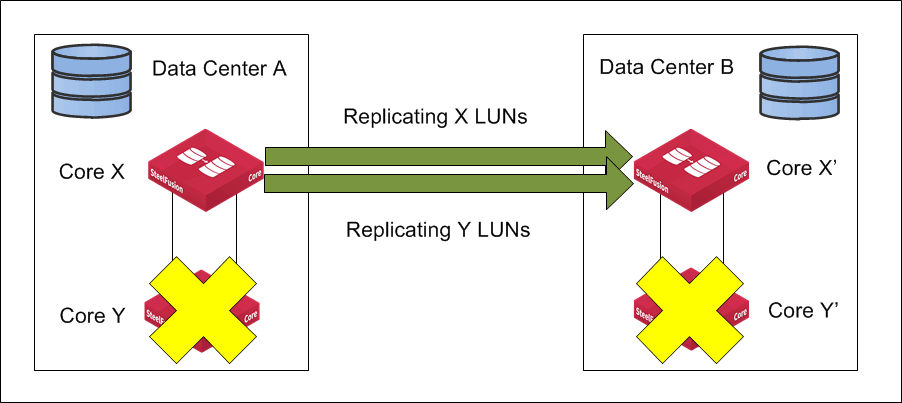
Figure: Core HA failover on primary and secondary data centers shows how HA failover on both sites is affecting replication. After Core Y and Core Y’ fail, Core X assumes the role of replication source and Core X’ assumes the role of replication target.
Figure: Core HA failover on primary and secondary data centers
SteelFusion replication metrics
When you deploy FusionSync between Cores in two data centers, you must understand some of the traffic workload and other metrics that occur on the link between the Cores to help with sizing and troubleshooting.
When FusionSync is running, the packets sent between the Cores consist of a very small header and payload. During the initial synchronization of a LUN from primary to secondary data center, the payload is fixed at 128 KB.
After the initial synchronization is complete and the LUNs are active, the payload size is exactly the same as the iSCSI write that occurred at the remote site. This write is the write between the iSCSI initiator of the server and the iSCSI target of the Edge. The actual size depends on the initiator and server operating system, but the payload size can be as large as 512 KB.
Whatever the payload size is between the primary and secondary, the Core honors the MTU setting of the network between data centers.
The maximum replication bandwidth consumed between the two data centers is the sum of the write throughput across all locations in which there are active SteelFusion Edge appliances installed. This maximum replication bandwidth is because all active branch locations are sending committed data to the Core in the primary data center, which is then sent on to the secondary data center. To reduce the quantity of traffic between data centers, use SteelHeads to perform data streamlining on the FusionSync traffic crossing the link between the two locations.
By default, each Core uses a single 1-Gbps network interface. A Core in the primary data center maintains two TCP replication connections for replication to the Core in the secondary data center. If you use multiple network interfaces on each Core, then multiple TCP connections share the available bandwidth on the link between data centers.
In general, the number of connections is calculated by using the following formula:
• Total replication connections = ((2 x number of replication interfaces) x number of Cores in primary) + ((2 x number of replication interfaces) x number of Cores in secondary)
For example, consider the following deployments:
• A single Core configured with one replication interface in the primary data center, and a single Core in the secondary data center, also with a single replication interface. In this scenario there would be two replication connections for the primary and two for the secondary, resulting in a total of four connections.
• Single Cores that each have two network interfaces would mean a total of (2 x 2) + (2 x 2) = 8 replication connections.
• Two Cores per data center, each with a single replication interface, means a total of (2 x 1) + (2 x 1) + (2 x 1) + (2 x 1) = 8 connections.
• A deployment with two Cores and two replication interfaces per data center has a total of (2 x 2) + (2 x 2) + (2 x 2) + (2 x 2) = 16 connections.
Journal LUN metrics
FusionSync requires the use of a Journal LUN within each data center. The LUN is only used when FusionSync is suspended between data centers. This section describes some of the Journal LUN metrics so that you can correctly size, provision, and maintain the Journal LUN.
Regardless of the number of LUNs in the data center that are being projected by Core and protected by FusionSync, you only need one Journal LUN for each data center. The LUN only needs to keep track of the write operations, so no actual data blocks are stored on the Journal LUN. Because no storage is required, the size of the Journal LUN is quite modest compared to the size of the LUNs on the backend storage array.
You can size the Journal LUN with this formula:
• 1 GB for metadata + 2 GB minimum for each LUN protected by FusionSync.
Therefore a SteelFusion deployment that has 25 LUNs needs a 51-GB Journal LUN.
The size of the Journal LUN is checked against the number of LUNs it is configured to support for FusionSync. If the size is too small, then an alert is raised and the FusionSync replication service does not start.
The Journal LUN can be thin-provisioned and, if required, it can also be dynamically increased in size.
Journal LUN-error handling is fairly extensive and generally tends to include checks for loss of connectivity and offlining, but it can include events such as out of storage, corruption, and shrinking size. In these cases, an alarm is raised on the Core that alerts to various conditions. For more details on error handling, see the SteelFusion Core Management Console User’s Guide.
Related information
• SteelFusion Core Management Console User’s Guide
• SteelFusion Edge Management Console User’s Guide
• SteelFusion Command-Line Interface Reference Manual
• Riverbed Splash at https://splash.riverbed.com/community/product-lines/steelfusion